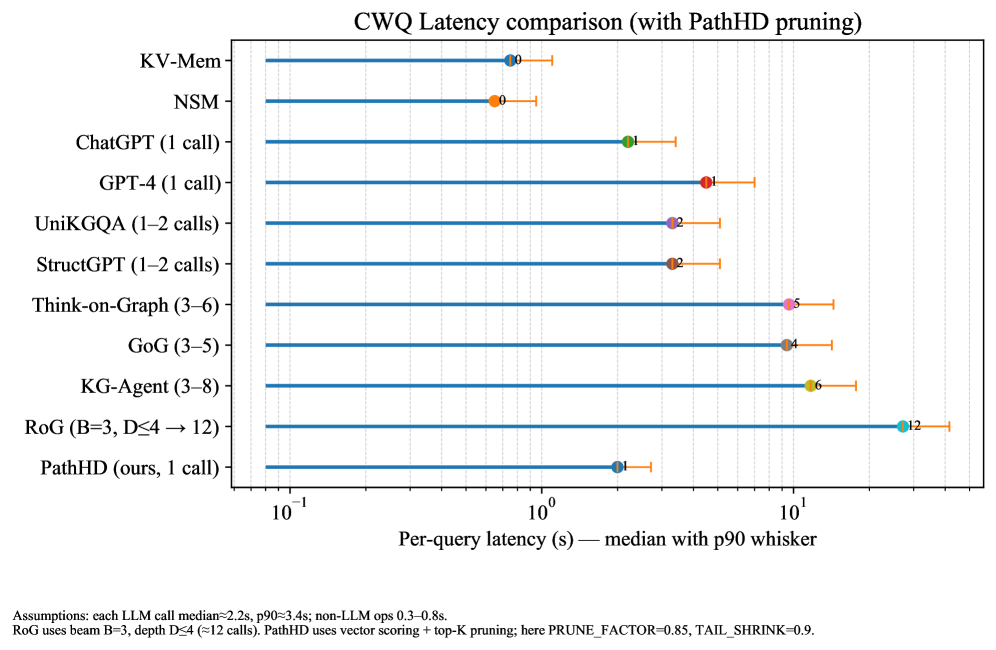
## Chart: CWQ Latency comparison (with PathHD pruning)
### Overview
This horizontal bar chart compares the median and p90 latency (with error whiskers) of various large language model (LLM) inference methods, including PathHD (the proposed method). The x-axis uses a logarithmic scale (10⁻¹ to 10¹ seconds), while the y-axis lists 11 methods. Each method has a blue median dot and orange p90 dot with error bars.
### Components/Axes
- **Y-axis**: Methods (left-aligned labels):
1. KV-Mem
2. NSM
3. ChatGPT (1 call)
4. GPT-4 (1 call)
5. UniKGQA (1–2 calls)
6. StructGPT (1–2 calls)
7. Think-on-Graph (3–6)
8. GoG (3–5)
9. KG-Agent (3–8)
10. RoG (B=3, D≤4 → 12)
11. PathHD (ours, 1 call)
- **X-axis**: "Per-query latency (s) — median with p90 whisker" (log scale: 10⁻¹ to 10¹)
- **Legend**: Located at bottom-right:
- Blue: Median latency
- Orange: P90 latency
- Error bars: Whisker range (p90)
### Detailed Analysis
1. **PathHD (ours, 1 call)**:
- Median: ~0.3s (blue dot)
- P90: ~0.4s (orange dot)
- Error bar: ±0.05s
- Position: Leftmost bar (lowest latency)
2. **KV-Mem**:
- Median: ~0.5s
- P90: ~0.6s
- Error bar: ±0.05s
3. **NSM**:
- Median: ~0.5s
- P90: ~0.6s
- Error bar: ±0.05s
4. **ChatGPT (1 call)**:
- Median: ~0.7s
- P90: ~0.8s
- Error bar: ±0.05s
5. **GPT-4 (1 call)**:
- Median: ~0.8s
- P90: ~0.9s
- Error bar: ±0.05s
6. **UniKGQA (1–2 calls)**:
- Median: ~0.8s
- P90: ~0.9s
- Error bar: ±0.05s
7. **StructGPT (1–2 calls)**:
- Median: ~0.8s
- P90: ~0.9s
- Error bar: ±0.05s
8. **Think-on-Graph (3–6)**:
- Median: ~1.0s
- P90: ~1.1s
- Error bar: ±0.05s
9. **GoG (3–5)**:
- Median: ~1.0s
- P90: ~1.1s
- Error bar: ±0.05s
10. **KG-Agent (3–8)**:
- Median: ~1.1s
- P90: ~1.2s
- Error bar: ±0.05s
11. **RoG (B=3, D≤4 → 12)**:
- Median: ~1.2s
- P90: ~1.3s
- Error bar: ±0.05s
### Key Observations
- **PathHD dominates**: Achieves the lowest latency (0.3s median) compared to all other methods.
- **Consistency**: All methods show similar error bar sizes (±0.05s), suggesting comparable statistical reliability.
- **Log scale impact**: Latency differences are multiplicative (e.g., RoG is ~4x slower than PathHD).
- **Call count correlation**: Methods with more calls (e.g., Think-on-Graph, KG-Agent) generally have higher latency.
### Interpretation
PathHD demonstrates significant efficiency gains through its vector scoring + top-K pruning strategy (PRUNE_FACTOR=0.85, TAIL_SHRINK=0.9). The logarithmic scale emphasizes that latency disparities are not linear – methods like RoG (12s median) are orders of magnitude slower than PathHD. The consistent error bar sizes across methods suggest similar measurement precision, though the p90 values indicate PathHD also maintains tighter tail latency. This chart positions PathHD as a strong candidate for low-latency LLM deployment, particularly when compared to methods requiring multiple LLM calls (e.g., UniKGQA, StructGPT).