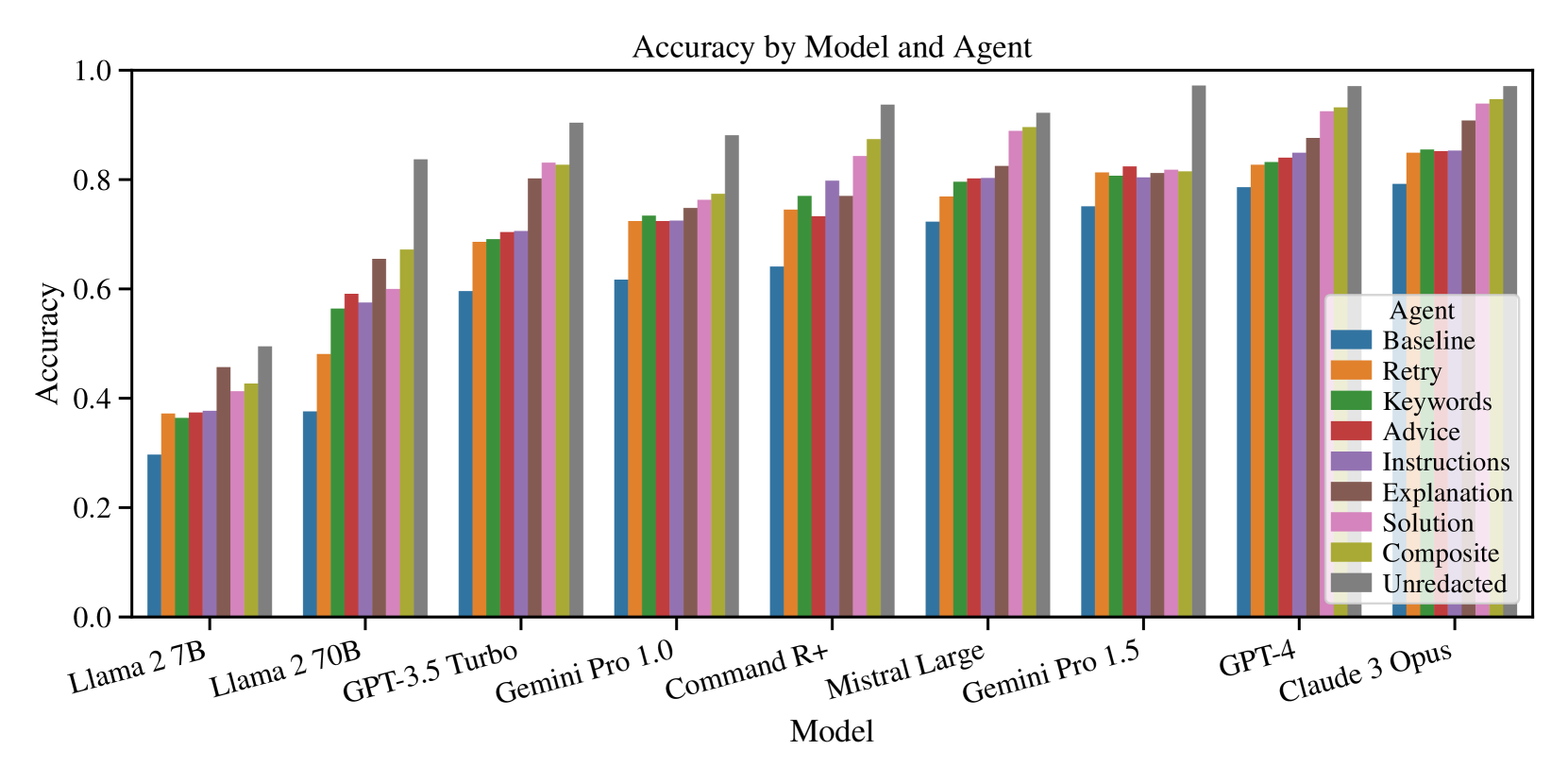
## Bar Chart: Accuracy by Model and Agent
### Overview
The image is a bar chart comparing the accuracy of different language models (Llama 2 7B, Llama 2 70B, GPT-3.5 Turbo, Gemini Pro 1.0, Command R+, Mistral Large, Gemini Pro 1.5, GPT-4, Claude 3 Opus) when using various prompting strategies ("Agents": Baseline, Retry, Keywords, Advice, Instructions, Explanation, Solution, Composite, Unredacted). The y-axis represents accuracy, ranging from 0.0 to 1.0. Each model has a cluster of bars, each representing a different agent.
### Components/Axes
* **Title:** Accuracy by Model and Agent
* **X-axis:** Model (Llama 2 7B, Llama 2 70B, GPT-3.5 Turbo, Gemini Pro 1.0, Command R+, Mistral Large, Gemini Pro 1.5, GPT-4, Claude 3 Opus)
* **Y-axis:** Accuracy (scale from 0.0 to 1.0, with increments of 0.2)
* **Legend (top-right):**
* Baseline (Blue)
* Retry (Orange)
* Keywords (Green)
* Advice (Red)
* Instructions (Purple)
* Explanation (Brown)
* Solution (Pink)
* Composite (Olive/Yellow-Green)
* Unredacted (Gray)
### Detailed Analysis
**Data Extraction and Trend Verification:**
* **Llama 2 7B:**
* Baseline (Blue): ~0.3
* Retry (Orange): ~0.37
* Keywords (Green): ~0.37
* Advice (Red): ~0.4
* Instructions (Purple): ~0.45
* Explanation (Brown): ~0.48
* Solution (Pink): ~0.4
* Composite (Olive/Yellow-Green): ~0.42
* Unredacted (Gray): ~0.5
* Trend: Accuracy increases from Baseline to Unredacted.
* **Llama 2 70B:**
* Baseline (Blue): ~0.37
* Retry (Orange): ~0.48
* Keywords (Green): ~0.55
* Advice (Red): ~0.58
* Instructions (Purple): ~0.6
* Explanation (Brown): ~0.65
* Solution (Pink): ~0.58
* Composite (Olive/Yellow-Green): ~0.6
* Unredacted (Gray): ~0.7
* Trend: Accuracy increases from Baseline to Unredacted.
* **GPT-3.5 Turbo:**
* Baseline (Blue): ~0.6
* Retry (Orange): ~0.68
* Keywords (Green): ~0.7
* Advice (Red): ~0.7
* Instructions (Purple): ~0.78
* Explanation (Brown): ~0.8
* Solution (Pink): ~0.7
* Composite (Olive/Yellow-Green): ~0.7
* Unredacted (Gray): ~0.83
* Trend: Accuracy increases from Baseline to Unredacted.
* **Gemini Pro 1.0:**
* Baseline (Blue): ~0.6
* Retry (Orange): ~0.72
* Keywords (Green): ~0.72
* Advice (Red): ~0.72
* Instructions (Purple): ~0.75
* Explanation (Brown): ~0.78
* Solution (Pink): ~0.72
* Composite (Olive/Yellow-Green): ~0.75
* Unredacted (Gray): ~0.88
* Trend: Accuracy increases from Baseline to Unredacted.
* **Command R+:**
* Baseline (Blue): ~0.6
* Retry (Orange): ~0.75
* Keywords (Green): ~0.75
* Advice (Red): ~0.75
* Instructions (Purple): ~0.78
* Explanation (Brown): ~0.8
* Solution (Pink): ~0.75
* Composite (Olive/Yellow-Green): ~0.78
* Unredacted (Gray): ~0.88
* Trend: Accuracy increases from Baseline to Unredacted.
* **Mistral Large:**
* Baseline (Blue): ~0.7
* Retry (Orange): ~0.78
* Keywords (Green): ~0.75
* Advice (Red): ~0.75
* Instructions (Purple): ~0.8
* Explanation (Brown): ~0.85
* Solution (Pink): ~0.78
* Composite (Olive/Yellow-Green): ~0.8
* Unredacted (Gray): ~0.9
* Trend: Accuracy increases from Baseline to Unredacted.
* **Gemini Pro 1.5:**
* Baseline (Blue): ~0.7
* Retry (Orange): ~0.8
* Keywords (Green): ~0.8
* Advice (Red): ~0.8
* Instructions (Purple): ~0.83
* Explanation (Brown): ~0.85
* Solution (Pink): ~0.8
* Composite (Olive/Yellow-Green): ~0.83
* Unredacted (Gray): ~0.95
* Trend: Accuracy increases from Baseline to Unredacted.
* **GPT-4:**
* Baseline (Blue): ~0.8
* Retry (Orange): ~0.8
* Keywords (Green): ~0.83
* Advice (Red): ~0.85
* Instructions (Purple): ~0.9
* Explanation (Brown): ~0.93
* Solution (Pink): ~0.85
* Composite (Olive/Yellow-Green): ~0.88
* Unredacted (Gray): ~0.98
* Trend: Accuracy increases from Baseline to Unredacted.
* **Claude 3 Opus:**
* Baseline (Blue): ~0.85
* Retry (Orange): ~0.85
* Keywords (Green): ~0.9
* Advice (Red): ~0.85
* Instructions (Purple): ~0.9
* Explanation (Brown): ~0.93
* Solution (Pink): ~0.85
* Composite (Olive/Yellow-Green): ~0.9
* Unredacted (Gray): ~0.95
* Trend: Accuracy increases from Baseline to Unredacted.
### Key Observations
* The "Unredacted" agent consistently yields the highest accuracy across all models.
* The "Baseline" agent generally results in the lowest accuracy.
* Accuracy generally increases as the models progress from Llama 2 7B to Claude 3 Opus.
* The difference in accuracy between different agents is more pronounced for weaker models like Llama 2 7B and Llama 2 70B.
### Interpretation
The chart demonstrates the impact of different prompting strategies ("Agents") on the accuracy of various language models. The "Unredacted" agent, which presumably involves providing the model with the complete, unaltered input, consistently outperforms other strategies. This suggests that providing more context or information to the model generally improves its performance. The "Baseline" agent, likely representing a minimal or default prompting approach, yields the lowest accuracy, highlighting the importance of effective prompt engineering. The trend of increasing accuracy from Llama 2 7B to Claude 3 Opus reflects the advancements in language model capabilities over time. The fact that the difference in accuracy between agents is more significant for weaker models suggests that prompt engineering plays a more crucial role in maximizing the performance of less capable models.