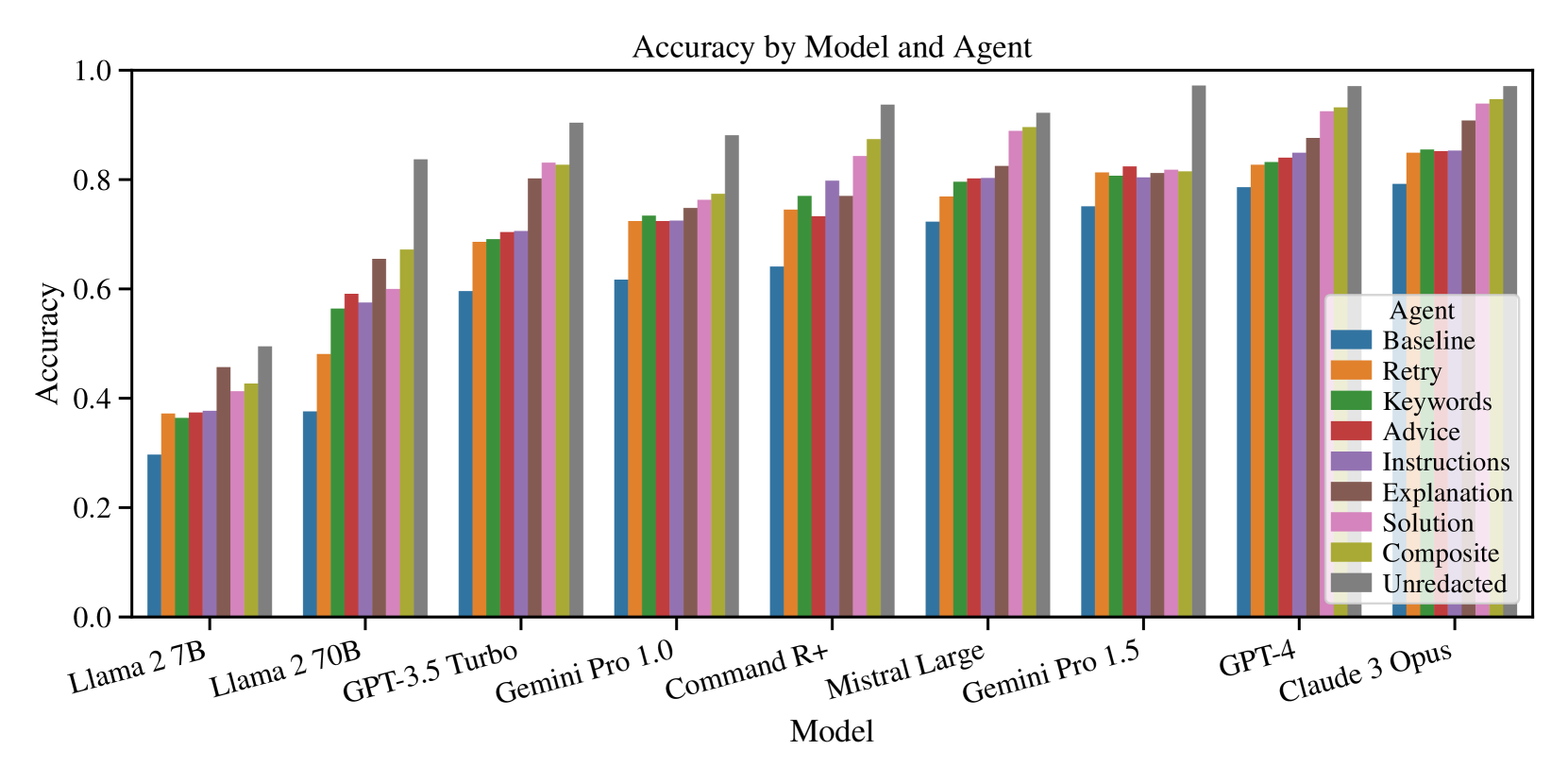
## Bar Chart: Accuracy by Model and Agent
### Overview
This bar chart visualizes the accuracy achieved by different language models when paired with various agent strategies. The x-axis represents the language model, and the y-axis represents the accuracy score, ranging from 0.0 to 1.0. Each model has a group of bars, each representing a different agent strategy.
### Components/Axes
* **Title:** Accuracy by Model and Agent
* **X-axis:** Model (Labels: Llama 2 7B, Llama 2 70B, GPT-3.5 Turbo, Gemini Pro 1.0, Command R+, Mistral Large, Gemini Pro 1.5, GPT-4, Claude 3 Opus)
* **Y-axis:** Accuracy (Scale: 0.0 to 1.0)
* **Legend:**
* Agent (Blue)
* Baseline (Orange)
* Retry (Yellow)
* Keywords (Red)
* Advice (Brown)
* Instructions (Dark Gray)
* Explanation (Light Gray)
* Solution (Purple)
* Composite (Green)
* Unredacted (Teal)
### Detailed Analysis
The chart consists of grouped bar plots for each model. I will analyze each model and its corresponding agent strategies. Note that values are approximate due to the resolution of the image.
* **Llama 2 7B:**
* Agent: ~0.48
* Baseline: ~0.45
* Retry: ~0.47
* Keywords: ~0.46
* Advice: ~0.44
* Instructions: ~0.43
* Explanation: ~0.42
* Solution: ~0.41
* Composite: ~0.40
* Unredacted: ~0.39
* **Llama 2 70B:**
* Agent: ~0.58
* Baseline: ~0.55
* Retry: ~0.57
* Keywords: ~0.56
* Advice: ~0.54
* Instructions: ~0.53
* Explanation: ~0.52
* Solution: ~0.51
* Composite: ~0.50
* Unredacted: ~0.49
* **GPT-3.5 Turbo:**
* Agent: ~0.75
* Baseline: ~0.72
* Retry: ~0.74
* Keywords: ~0.73
* Advice: ~0.71
* Instructions: ~0.70
* Explanation: ~0.69
* Solution: ~0.68
* Composite: ~0.67
* Unredacted: ~0.66
* **Gemini Pro 1.0:**
* Agent: ~0.78
* Baseline: ~0.75
* Retry: ~0.77
* Keywords: ~0.76
* Advice: ~0.74
* Instructions: ~0.73
* Explanation: ~0.72
* Solution: ~0.71
* Composite: ~0.70
* Unredacted: ~0.69
* **Command R+:**
* Agent: ~0.72
* Baseline: ~0.69
* Retry: ~0.71
* Keywords: ~0.70
* Advice: ~0.68
* Instructions: ~0.67
* Explanation: ~0.66
* Solution: ~0.65
* Composite: ~0.64
* Unredacted: ~0.63
* **Mistral Large:**
* Agent: ~0.85
* Baseline: ~0.82
* Retry: ~0.84
* Keywords: ~0.83
* Advice: ~0.81
* Instructions: ~0.80
* Explanation: ~0.79
* Solution: ~0.78
* Composite: ~0.77
* Unredacted: ~0.76
* **Gemini Pro 1.5:**
* Agent: ~0.88
* Baseline: ~0.85
* Retry: ~0.87
* Keywords: ~0.86
* Advice: ~0.84
* Instructions: ~0.83
* Explanation: ~0.82
* Solution: ~0.81
* Composite: ~0.80
* Unredacted: ~0.79
* **GPT-4:**
* Agent: ~0.92
* Baseline: ~0.89
* Retry: ~0.91
* Keywords: ~0.90
* Advice: ~0.88
* Instructions: ~0.87
* Explanation: ~0.86
* Solution: ~0.85
* Composite: ~0.84
* Unredacted: ~0.83
* **Claude 3 Opus:**
* Agent: ~0.95
* Baseline: ~0.92
* Retry: ~0.94
* Keywords: ~0.93
* Advice: ~0.91
* Instructions: ~0.90
* Explanation: ~0.89
* Solution: ~0.88
* Composite: ~0.87
* Unredacted: ~0.86
### Key Observations
* Accuracy generally increases with more powerful models (moving from left to right on the x-axis).
* The "Agent" strategy consistently outperforms other strategies across all models.
* The difference in accuracy between strategies is more pronounced for stronger models.
* Llama 2 7B and Llama 2 70B have significantly lower accuracy scores compared to the other models.
* The "Unredacted" strategy consistently has the lowest accuracy across all models.
### Interpretation
The data demonstrates a clear correlation between model capability and accuracy when combined with different agent strategies. More advanced models like Claude 3 Opus and GPT-4 achieve significantly higher accuracy scores than less powerful models like Llama 2 7B. The "Agent" strategy appears to be the most effective overall, suggesting that a well-designed agent can significantly improve the performance of a language model. The consistently lower performance of the "Unredacted" strategy suggests that redacting information may be beneficial for certain tasks, potentially by reducing noise or ambiguity. The increasing gap in performance between strategies as model capability increases suggests that more powerful models are better able to leverage the benefits of sophisticated agent strategies. This data could be used to inform the selection of appropriate models and agent strategies for specific applications, optimizing for accuracy and performance. The consistent trend across all models suggests a robust relationship between these variables.