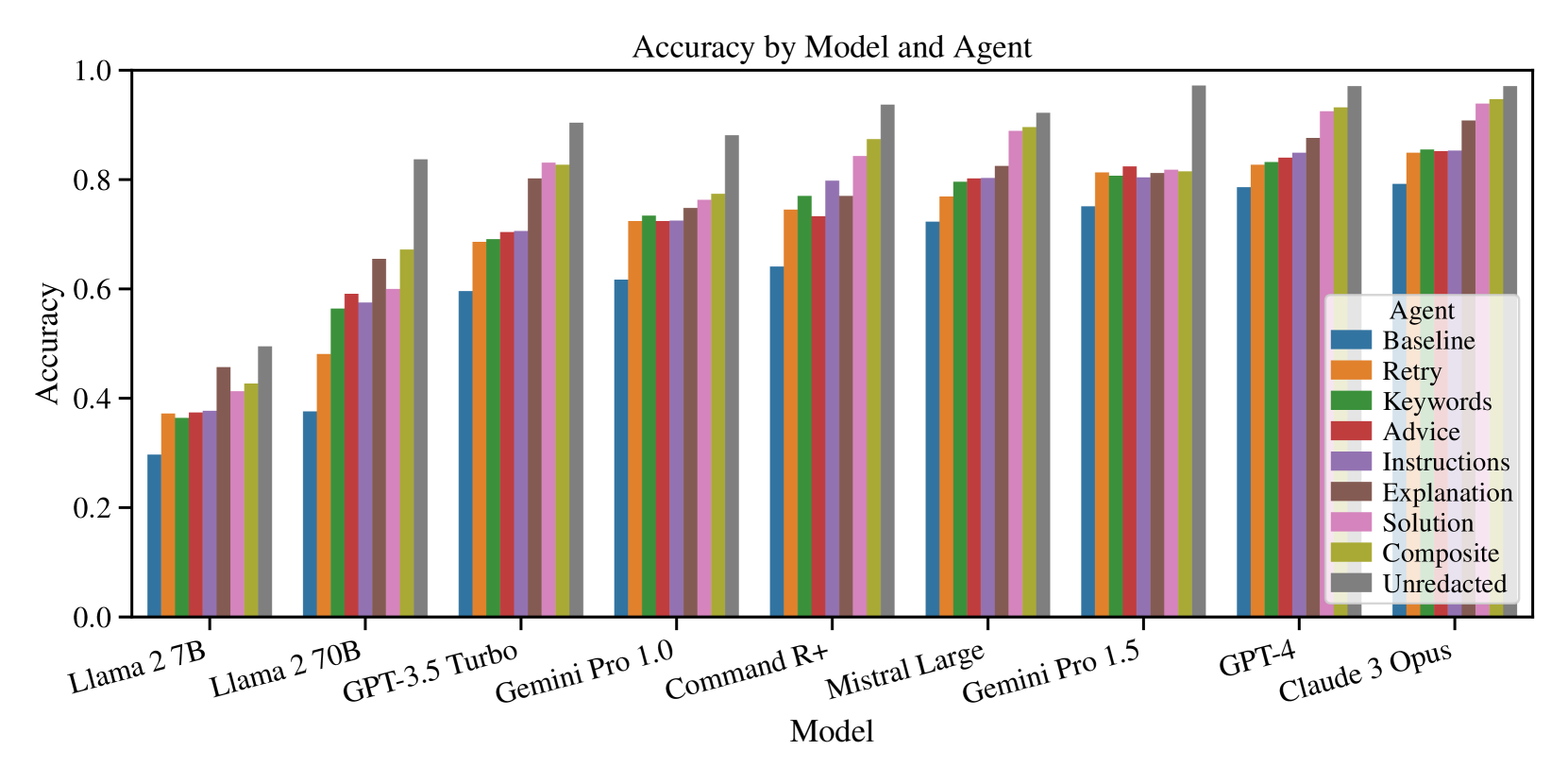
## Bar Chart: Accuracy by Model and Agent
### Overview
The chart compares the accuracy of various AI models (x-axis) across different agent types (y-axis). Each model is evaluated using eight agent configurations, with accuracy scores ranging from 0.0 to 1.0. The data suggests a correlation between model complexity and agent performance, with larger models generally achieving higher accuracy.
### Components/Axes
- **X-axis (Models)**:
- Llama 2 7B
- Llama 2 70B
- GPT-3.5 Turbo
- Gemini Pro 1.0
- Command R+
- Mistral Large
- Gemini Pro 1.5
- GPT-4
- Claude 3 Opus
- **Y-axis (Accuracy)**: 0.0 to 1.0 in increments of 0.2
- **Legend (Agents)**:
- Blue: Baseline
- Orange: Retry
- Green: Keywords
- Red: Advice
- Purple: Instructions
- Brown: Explanation
- Pink: Solution
- Olive: Composite
- Gray: Unredacted
### Detailed Analysis
1. **Llama 2 7B**:
- Baseline: ~0.3
- Retry: ~0.4
- Keywords: ~0.4
- Advice: ~0.4
- Instructions: ~0.4
- Explanation: ~0.5
- Solution: ~0.5
- Composite: ~0.5
- Unredacted: ~0.5
2. **Llama 2 70B**:
- Baseline: ~0.4
- Retry: ~0.5
- Keywords: ~0.6
- Advice: ~0.6
- Instructions: ~0.6
- Explanation: ~0.7
- Solution: ~0.7
- Composite: ~0.7
- Unredacted: ~0.8
3. **GPT-3.5 Turbo**:
- Baseline: ~0.6
- Retry: ~0.7
- Keywords: ~0.7
- Advice: ~0.7
- Instructions: ~0.7
- Explanation: ~0.8
- Solution: ~0.8
- Composite: ~0.8
- Unredacted: ~0.9
4. **Gemini Pro 1.0**:
- Baseline: ~0.6
- Retry: ~0.7
- Keywords: ~0.7
- Advice: ~0.7
- Instructions: ~0.7
- Explanation: ~0.8
- Solution: ~0.8
- Composite: ~0.8
- Unredacted: ~0.9
5. **Command R+**:
- Baseline: ~0.6
- Retry: ~0.7
- Keywords: ~0.7
- Advice: ~0.7
- Instructions: ~0.7
- Explanation: ~0.8
- Solution: ~0.8
- Composite: ~0.8
- Unredacted: ~0.9
6. **Mistral Large**:
- Baseline: ~0.7
- Retry: ~0.8
- Keywords: ~0.8
- Advice: ~0.8
- Instructions: ~0.8
- Explanation: ~0.9
- Solution: ~0.9
- Composite: ~0.9
- Unredacted: ~0.9
7. **Gemini Pro 1.5**:
- Baseline: ~0.7
- Retry: ~0.8
- Keywords: ~0.8
- Advice: ~0.8
- Instructions: ~0.8
- Explanation: ~0.9
- Solution: ~0.9
- Composite: ~0.9
- Unredacted: ~0.9
8. **GPT-4**:
- Baseline: ~0.8
- Retry: ~0.8
- Keywords: ~0.8
- Advice: ~0.8
- Instructions: ~0.8
- Explanation: ~0.9
- Solution: ~0.9
- Composite: ~0.9
- Unredacted: ~0.9
9. **Claude 3 Opus**:
- Baseline: ~0.8
- Retry: ~0.8
- Keywords: ~0.8
- Advice: ~0.8
- Instructions: ~0.8
- Explanation: ~0.9
- Solution: ~0.9
- Composite: ~0.9
- Unredacted: ~0.9
### Key Observations
- **Model Size Correlation**: Larger models (e.g., GPT-4, Claude 3 Opus) consistently outperform smaller models (e.g., Llama 2 7B) across all agent types.
- **Agent Performance**: The Composite agent achieves the highest accuracy in most cases, followed by Unredacted. Baseline agents perform the worst.
- **Trend**: Accuracy improves with model complexity, with smaller models showing minimal variation between agents.
### Interpretation
The data demonstrates that model architecture and size significantly influence accuracy, with larger models achieving near-optimal performance across all agent configurations. The Composite agent's consistent superiority suggests it is particularly effective at leveraging model capabilities. The Baseline agent's poor performance highlights the importance of specialized agent configurations for task-specific accuracy. This analysis underscores the need for model selection based on task complexity and the value of agent optimization for maximizing performance.