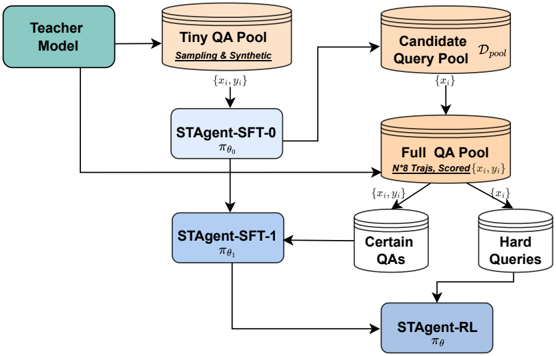
## Flowchart: STAgent Training Pipeline
### Overview
The diagram illustrates a multi-stage training pipeline for a question-answering (QA) system called STAgent. It begins with a Teacher Model and progresses through iterative refinement of query-answer pairs (QAs) and model training phases. The pipeline emphasizes hierarchical data curation and model adaptation, culminating in a reinforcement learning (RL) stage.
### Components/Axes
- **Key Components**:
- **Teacher Model**: Initial data source.
- **Tiny QA Pool**: Contains sampled/synthetic QA pairs `{x_i, y_i}`.
- **Candidate Query Pool**: Derived from Tiny QA Pool, labeled `{x_i}`.
- **Full QA Pool**: Aggregates N*8 Trajs, Scored QA pairs `{x_i, y_i}`.
- **Certain QAs**: Subset of Full QA Pool with high confidence.
- **Hard Queries**: Subset of Full QA Pool with low confidence.
- **STAgent-SFT-0**: Initial supervised fine-tuning (SFT) model with parameters `π_θ₀`.
- **STAgent-SFT-1**: Second SFT iteration with parameters `π_θ₁`.
- **STAgent-RL**: Final RL-trained model with parameters `π_θ`.
- **Flow Direction**:
- Arrows indicate data flow and training progression (left to right, top to bottom).
### Detailed Analysis
1. **Data Flow**:
- The Teacher Model generates the Tiny QA Pool via sampling and synthetic data.
- The Candidate Query Pool (`{x_i}`) is extracted from the Tiny QA Pool.
- The Full QA Pool combines N*8 Trajs, Scored QA pairs, sourced from both the Candidate Query Pool and Tiny QA Pool.
- The Full QA Pool is split into **Certain QAs** (high-confidence pairs) and **Hard Queries** (low-confidence pairs).
2. **Model Training**:
- **STAgent-SFT-0**: Trained on the Tiny QA Pool using SFT with initial parameters `π_θ₀`.
- **STAgent-SFT-1**: Further refined using SFT on the Candidate Query Pool, updating parameters to `π_θ₁`.
- **STAgent-RL**: Final model trained via RL on the Full QA Pool, integrating insights from both Certain QAs and Hard Queries.
3. **Key Relationships**:
- The Tiny QA Pool serves as the foundational dataset for subsequent stages.
- The Full QA Pool acts as a comprehensive evaluation/test set for the RL phase.
- STAgent-RL integrates feedback from both Certain QAs (reliable) and Hard Queries (challenging) to optimize performance.
### Key Observations
- **Hierarchical Refinement**: The pipeline progresses from simple sampling (Tiny QA Pool) to complex RL training (STAgent-RL), suggesting iterative improvement.
- **Data Segmentation**: Splitting the Full QA Pool into Certain QAs and Hard Queries implies a focus on balancing easy and difficult examples during RL.
- **Model Evolution**: The transition from SFT-0 to SFT-1 to RL indicates a staged approach to model adaptation, with SFT providing initial supervision and RL enabling dynamic learning.
### Interpretation
This pipeline demonstrates a structured approach to training a robust QA system. By starting with a Teacher Model and iteratively refining data and models, the design prioritizes scalability and adaptability. The use of SFT for initial training and RL for final optimization aligns with modern NLP practices, where supervised learning establishes a baseline, and RL fine-tunes performance on real-world complexity. The segmentation of the Full QA Pool into Certain QAs and Hard Queries highlights an awareness of data quality and difficulty, ensuring the model is tested and improved across diverse scenarios. The absence of explicit numerical values suggests the diagram emphasizes architectural design over empirical results, focusing on conceptual flow rather than quantitative metrics.