## Example Analysis: Language Model Answer Evaluation
### Overview
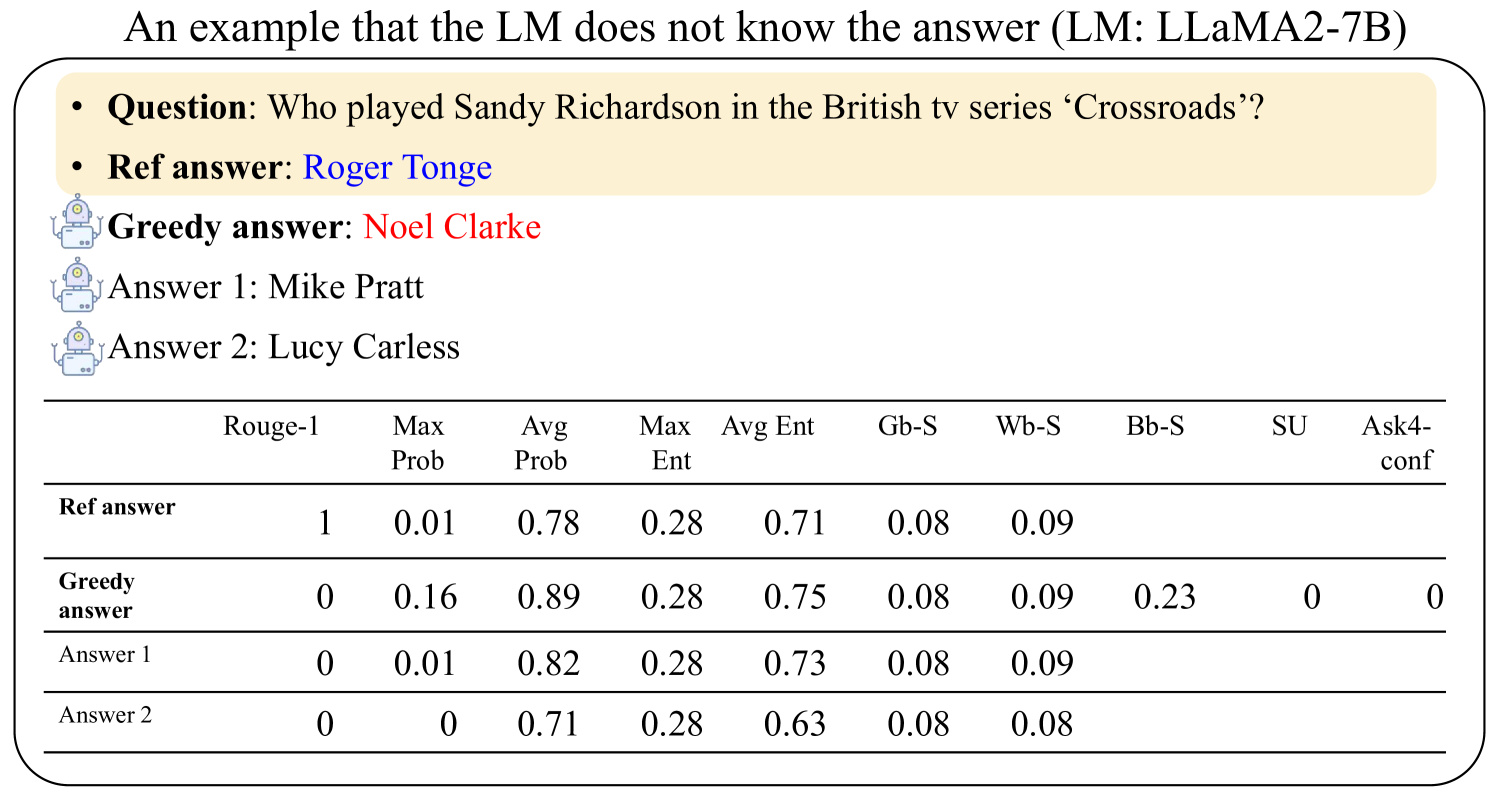
The image presents an example where a Language Model (LM), specifically LLaMA2-7B, fails to provide the correct answer to a question. It includes the question, the reference answer, the LM's greedy answer, and two other possible answers. A table provides various metrics for each answer, including Rouge-1 score, maximum probability, average probability, maximum entropy, average entropy, and other statistical measures.
### Components/Axes
* **Title:** "An example that the LM does not know the answer (LM: LLaMA2-7B)"
* **Question:** "Who played Sandy Richardson in the British tv series 'Crossroads'?"
* **Reference Answer:** "Roger Tonge"
* **Greedy Answer:** "Noel Clarke"
* **Answer 1:** "Mike Pratt"
* **Answer 2:** "Lucy Carless"
* **Table Headers:**
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Table Rows:**
* Ref answer
* Greedy answer
* Answer 1
* Answer 2
### Detailed Analysis or ### Content Details
**Table Data:**
| Metric | Ref answer | Greedy answer | Answer 1 | Answer 2 |
| ----------- | ---------- | ------------- | -------- | -------- |
| Rouge-1 | 1 | 0 | 0 | 0 |
| Max Prob | 0.01 | 0.16 | 0.01 | 0 |
| Avg Prob | 0.78 | 0.89 | 0.82 | 0.71 |
| Max Ent | 0.28 | 0.28 | 0.28 | 0.28 |
| Avg Ent | 0.71 | 0.75 | 0.73 | 0.63 |
| Gb-S | 0.08 | 0.08 | 0.08 | 0.08 |
| Wb-S | 0.09 | 0.09 | 0.09 | 0.08 |
| Bb-S | N/A | 0.23 | N/A | N/A |
| SU | N/A | 0 | N/A | N/A |
| Ask4-conf | N/A | 0 | N/A | N/A |
* **Rouge-1:** The reference answer has a perfect score of 1, while all other answers have a score of 0.
* **Max Prob:** The greedy answer has the highest maximum probability at 0.16. The reference answer and Answer 1 both have a max probability of 0.01, while Answer 2 has a max probability of 0.
* **Avg Prob:** The greedy answer has the highest average probability at 0.89. Answer 1 has an average probability of 0.82, the reference answer has 0.78, and Answer 2 has 0.71.
* **Max Ent:** All answers have the same maximum entropy of 0.28.
* **Avg Ent:** The greedy answer has the highest average entropy at 0.75. Answer 1 has an average entropy of 0.73, the reference answer has 0.71, and Answer 2 has 0.63.
* **Gb-S:** All answers have the same Gb-S score of 0.08.
* **Wb-S:** The reference answer, greedy answer, and Answer 1 all have a Wb-S score of 0.09, while Answer 2 has a score of 0.08.
* **Bb-S:** The greedy answer has a Bb-S score of 0.23.
* **SU:** The greedy answer has an SU score of 0.
* **Ask4-conf:** The greedy answer has an Ask4-conf score of 0.
### Key Observations
* The LM's "greedy answer" (Noel Clarke) has a Rouge-1 score of 0, indicating it's completely incorrect.
* The "greedy answer" has the highest Max Prob and Avg Prob, suggesting the LM was most confident in this incorrect answer.
* The reference answer has a perfect Rouge-1 score of 1, as expected.
### Interpretation
The data demonstrates a failure case for the LLaMA2-7B model. Despite having relatively high average and maximum probabilities for its "greedy answer," the model failed to provide the correct answer to the question. This highlights the limitations of relying solely on probability scores for evaluating the correctness of LM-generated answers. The Rouge-1 score accurately reflects the correctness of the reference answer and the incorrectness of the other answers. The other metrics (entropy, Gb-S, Wb-S, Bb-S, SU, Ask4-conf) provide additional information about the characteristics of the answers, but the Rouge-1 score is the most direct indicator of accuracy in this case.