\n
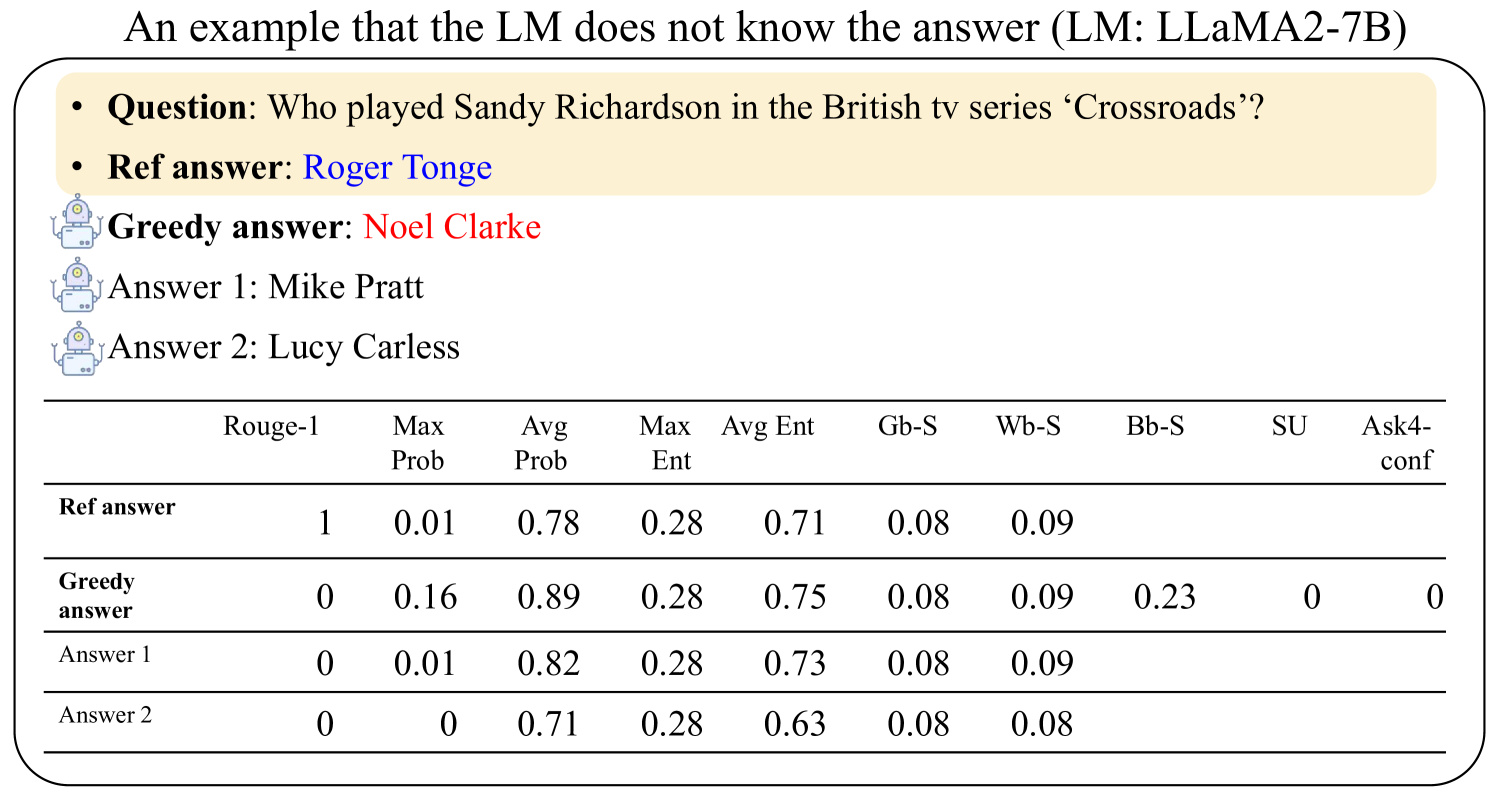
## Data Table: LLM Answer Evaluation
### Overview
This image presents a data table evaluating the performance of a Large Language Model (LLM), specifically LLaMA2-7B, on a question-answering task. The question is "Who played Sandy Richardson in the British tv series ‘Crossroads’?". The table compares the LLM's "Greedy answer" and two alternative answers ("Answer 1", "Answer 2") against a "Ref answer" (reference answer). The evaluation is based on several metrics: Rouge-1, Max Prob, Avg Prob, Max Ent, Avg Ent, Gb-S, Wb-S, Bb-S, SU, and Ask4-conf.
### Components/Axes
* **Rows:** Represent the different answers being evaluated: "Ref answer", "Greedy answer", "Answer 1", and "Answer 2".
* **Columns:** Represent the evaluation metrics:
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Header:** Contains the metric names.
* **Question:** "Who played Sandy Richardson in the British tv series ‘Crossroads’?"
* **Ref answer:** "Roger Tonge"
* **Greedy answer:** "Noel Clarke"
* **Answer 1:** "Mike Pratt"
* **Answer 2:** "Lucy Carless"
### Detailed Analysis or Content Details
The data table contains numerical values for each answer across the different metrics. Here's a breakdown of the values:
| Answer | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|---------------|---------|----------|----------|---------|---------|------|------|------|----|-----------|
| Ref answer | 1 | 0.01 | 0.78 | 0.28 | 0.71 | 0.08 | 0.09 | | | |
| Greedy answer | 0 | 0.16 | 0.89 | 0.28 | 0.75 | 0.08 | 0.09 | 0.23 | 0 | 0 |
| Answer 1 | 0 | 0.01 | 0.82 | 0.28 | 0.73 | 0.08 | 0.09 | | | |
| Answer 2 | 0 | 0 | 0.71 | 0.28 | 0.63 | 0.08 | 0.08 | | | |
* **Rouge-1:** The "Ref answer" has a value of 1, while all other answers have a value of 0.
* **Max Prob:** "Greedy answer" has the highest value (0.16), followed by "Answer 1" (0.01), and "Answer 2" (0). "Ref answer" has a value of 0.01.
* **Avg Prob:** "Greedy answer" has the highest value (0.89), followed by "Answer 1" (0.82), "Ref answer" (0.78), and "Answer 2" (0.71).
* **Max Ent:** All answers have a value of 0.28.
* **Avg Ent:** "Ref answer" has the highest value (0.71), followed by "Greedy answer" (0.75), "Answer 1" (0.73), and "Answer 2" (0.63).
* **Gb-S:** All answers have a value of 0.08.
* **Wb-S:** "Ref answer", "Greedy answer", and "Answer 1" have a value of 0.09, while "Answer 2" has a value of 0.08.
* **Bb-S:** "Greedy answer" has a value of 0.23, while the other answers have no value listed.
* **SU:** "Greedy answer" has a value of 0, while the other answers have no value listed.
* **Ask4-conf:** "Greedy answer" has a value of 0, while the other answers have no value listed.
### Key Observations
* The "Ref answer" achieves a perfect score (1) on the Rouge-1 metric, indicating a complete match with the expected answer.
* The "Greedy answer" performs best on Max Prob and Avg Prob, suggesting it has a higher confidence in its answer, but it fails on Rouge-1.
* "Answer 2" consistently has the lowest values across most metrics.
* Several metrics (Bb-S, SU, Ask4-conf) are only populated for the "Greedy answer".
### Interpretation
The data suggests that the LLM (LLaMA2-7B) struggles with this specific question. While the "Greedy answer" (Noel Clarke) has a high probability score, it is incorrect according to the reference answer (Roger Tonge). The Rouge-1 score of 0 for the "Greedy answer" confirms this. The high Avg Prob for the "Greedy answer" might indicate the model is overconfident in an incorrect response. The fact that the "Ref answer" has a Rouge-1 score of 1 indicates that the model *can* provide correct answers, but in this case, it did not. The missing values for some metrics in the "Ref answer", "Answer 1", and "Answer 2" rows could indicate that these metrics are only calculated for the "Greedy answer" or that the values are below a certain threshold. The data highlights the importance of evaluating LLMs not just on confidence scores (probabilities) but also on the accuracy of their responses (Rouge-1).