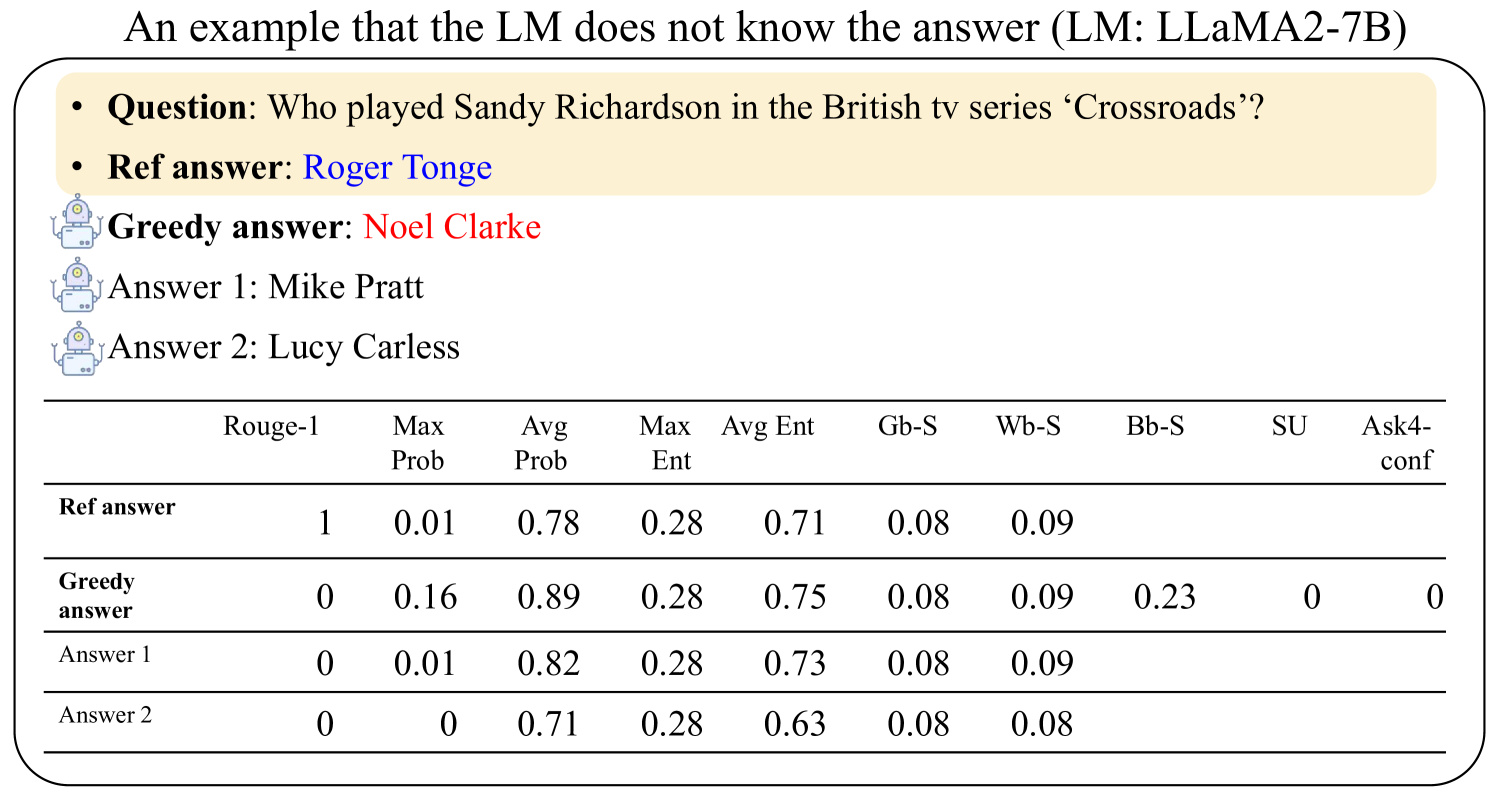
## Screenshot: LLM Answer Evaluation Example (LLaMA2-7B)
### Overview
This image demonstrates a failure case of a large language model (LLM) answering a factual question about a TV series character. The example shows the question, reference answer, and three competing answers generated by the model, along with a detailed metrics table comparing their performance across multiple evaluation dimensions.
### Components/Axes
1. **Question**: "Who played Sandy Richardson in the British tv series ‘Crossroads’?"
2. **Reference Answer**: Roger Tonge (correct answer)
3. **Greedy Answer**: Noel Clarke (incorrect)
4. **Answer 1**: Mike Pratt (incorrect)
5. **Answer 2**: Lucy Carless (incorrect)
**Metrics Table**:
| Metric | Reference Answer | Greedy Answer | Answer 1 | Answer 2 |
|--------------|------------------|---------------|----------|----------|
| Rouge-1 | 1.00 | 0.00 | 0.00 | 0.00 |
| Max Prob | 0.01 | 0.16 | 0.01 | 0.00 |
| Avg Prob | 0.78 | 0.89 | 0.82 | 0.71 |
| Max Ent | 0.28 | 0.28 | 0.28 | 0.28 |
| Avg Ent | 0.71 | 0.75 | 0.73 | 0.63 |
| Gb-S | 0.08 | 0.08 | 0.08 | 0.08 |
| Wb-S | 0.09 | 0.09 | 0.09 | 0.08 |
| Bb-S | 0.23 | 0.23 | 0.23 | 0.23 |
| SU | 0 | 0 | 0 | 0 |
| Ask4-conf | 0 | 0 | 0 | 0 |
### Key Observations
1. The reference answer achieves perfect Rouge-1 score (1.00) but has the lowest Max Prob (0.01) and Avg Prob (0.78) among all answers.
2. The greedy answer (Noel Clarke) has the highest Max Prob (0.16) and Avg Prob (0.89), but scores 0 on Rouge-1.
3. All answers share identical Gb-S, Wb-S, and Bb-S scores (0.08-0.09), suggesting similar surface-level linguistic properties.
4. The reference answer has the highest Bb-S score (0.23) despite being the only correct answer.
5. All answers show zero SU (semantic understanding) and Ask4-conf scores, indicating the model's inability to assess answer correctness.
### Interpretation
This example reveals critical limitations in the LLM's answer selection mechanism:
1. **Probability vs. Accuracy**: The greedy answer with highest probabilities (Noel Clarke) is completely wrong, while the correct answer (Roger Tonge) has the lowest probabilities.
2. **Metric Misalignment**: Surface metrics like Gb-S and Wb-S fail to distinguish correct from incorrect answers, while Rouge-1 perfectly identifies the reference answer.
3. **Confidence Paradox**: The model shows no confidence (Ask4-conf=0) in any answer despite generating multiple responses, suggesting flawed calibration.
4. **Entropy Patterns**: All answers share identical Max Ent (0.28), indicating similar uncertainty levels despite differing correctness.
The data demonstrates that relying solely on probability scores or surface metrics can lead to catastrophic failures in factual QA systems. The reference answer's perfect Rouge-1 score highlights the importance of exact match metrics, while the identical surface metrics across answers expose the model's inability to distinguish correctness through linguistic properties alone.