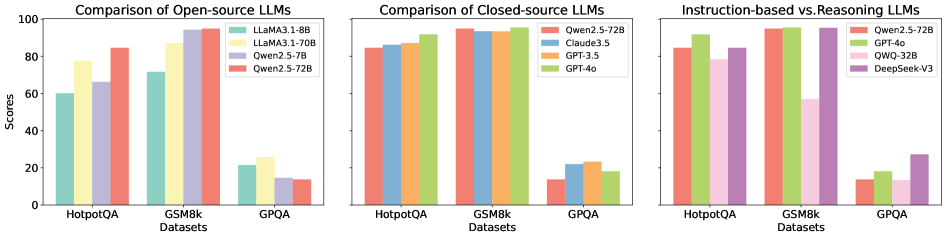
## Bar Chart: Comparison of LLMs Across Datasets
### Overview
The image presents a comparative analysis of large language models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. It evaluates performance scores (0-100) for open-source, closed-source, and instruction-based vs. reasoning LLMs. Three distinct sections visualize model performance, with color-coded bars representing different models.
### Components/Axes
- **X-Axis (Datasets)**: HotpotQA, GSM8k, GPQA (categorical, left-to-right).
- **Y-Axis (Scores)**: 0-100 (linear scale, increments of 20).
- **Legends**:
1. **Open-source LLMs**:
- LLaMA3.1-8B (green)
- LLaMA3.1-70B (yellow)
- Qwen2.5-72B (red)
2. **Closed-source LLMs**:
- Qwen2.5-72B (red)
- Claude3.5 (blue)
- GPT-3.5 (orange)
- GPT-4o (green)
3. **Instruction-based vs. Reasoning LLMs**:
- Qwen2.5-72B (red)
- GPT-4o (green)
- QWQ-32B (pink)
- DeepSeek-V3 (purple)
### Detailed Analysis
#### Open-source LLMs
- **HotpotQA**:
- LLaMA3.1-8B: ~60
- LLaMA3.1-70B: ~80
- Qwen2.5-72B: ~85
- **GSM8k**:
- LLaMA3.1-8B: ~70
- LLaMA3.1-70B: ~90
- Qwen2.5-72B: ~95
- **GPQA**:
- LLaMA3.1-8B: ~20
- LLaMA3.1-70B: ~25
- Qwen2.5-72B: ~15
#### Closed-source LLMs
- **HotpotQA**:
- Qwen2.5-72B: ~85
- Claude3.5: ~88
- GPT-3.5: ~87
- GPT-4o: ~90
- **GSM8k**:
- Qwen2.5-72B: ~95
- Claude3.5: ~92
- GPT-3.5: ~90
- GPT-4o: ~93
- **GPQA**:
- Qwen2.5-72B: ~15
- Claude3.5: ~20
- GPT-3.5: ~18
- GPT-4o: ~17
#### Instruction-based vs. Reasoning LLMs
- **HotpotQA**:
- Qwen2.5-72B: ~85
- GPT-4o: ~90
- QWQ-32B: ~75
- DeepSeek-V3: ~60
- **GSM8k**:
- Qwen2.5-72B: ~95
- GPT-4o: ~93
- QWQ-32B: ~80
- DeepSeek-V3: ~70
- **GPQA**:
- Qwen2.5-72B: ~15
- GPT-4o: ~17
- QWQ-32B: ~12
- DeepSeek-V3: ~25
### Key Observations
1. **Open-source models** perform best on **GSM8k** (e.g., Qwen2.5-72B: 95) but struggle on **GPQA** (e.g., LLaMA3.1-70B: 25).
2. **Closed-source models** dominate **GSM8k** (GPT-4o: 93) and **HotpotQA** (GPT-4o: 90), with minimal performance drop on GPQA.
3. **Instruction-based models** (Qwen2.5-72B, GPT-4o) consistently outperform **reasoning models** (QWQ-32B, DeepSeek-V3) across datasets.
4. **GPQA** scores are universally low, suggesting it tests specialized capabilities not emphasized in other datasets.
### Interpretation
The data highlights a clear performance hierarchy:
- **Closed-source models** (e.g., GPT-4o, Qwen2.5-72B) excel in reasoning tasks (GSM8k) and general knowledge (HotpotQA), likely due to larger training data and optimization.
- **Instruction-based models** maintain higher scores than reasoning models, indicating that instruction tuning improves adaptability.
- **GPQA** acts as an outlier, with all models scoring poorly, possibly reflecting its focus on graduate-level problem-solving requiring deeper reasoning or domain-specific knowledge.
This analysis underscores the trade-offs between open-source and closed-source models, with closed-source systems currently leading in standardized reasoning benchmarks. The disparity in GPQA scores suggests a need for further research into specialized training methodologies for complex problem-solving.