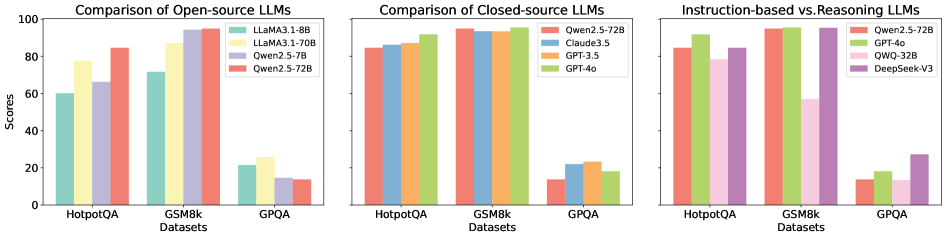
## Bar Chart: LLM Performance Comparison
### Overview
The image presents three bar charts comparing the performance of various Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The charts are arranged horizontally, with the first comparing open-source LLMs, the second comparing closed-source LLMs, and the third comparing instruction-based and reasoning LLMs. The y-axis represents "Scores," ranging from 0 to 100.
### Components/Axes
* **X-axis:** Datasets - HotpotQA, GSM8k, GPQA.
* **Y-axis:** Scores - Scale from 0 to 100, incrementing by 20.
* **Chart 1 (Open-source LLMs):**
* LLaMA3-1.8B (Blue)
* LLaMA3-70B (Yellow)
* Qwen2.5-7B (Light Blue)
* Qwen2.5-72B (Pink)
* **Chart 2 (Closed-source LLMs):**
* Qwen2.5-72B (Green)
* Claude3.5 (Orange)
* GPT-3.5 (Light Orange)
* GPT-4o (Brown)
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* Qwen2.5-72B (Light Green)
* GPT-4o (Yellow-Green)
* QWQ-32B (Purple)
* DeepSeekV3 (Gray)
### Detailed Analysis or Content Details
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:** LLaMA3-1.8B scores approximately 62. LLaMA3-70B scores approximately 82. Qwen2.5-7B scores approximately 72. Qwen2.5-72B scores approximately 88.
* **GSM8k:** LLaMA3-1.8B scores approximately 22. LLaMA3-70B scores approximately 80. Qwen2.5-7B scores approximately 70. Qwen2.5-72B scores approximately 90.
* **GPQA:** LLaMA3-1.8B scores approximately 12. LLaMA3-70B scores approximately 26. Qwen2.5-7B scores approximately 20. Qwen2.5-72B scores approximately 16.
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:** Qwen2.5-72B scores approximately 86. Claude3.5 scores approximately 88. GPT-3.5 scores approximately 82. GPT-4o scores approximately 94.
* **GSM8k:** Qwen2.5-72B scores approximately 92. Claude3.5 scores approximately 94. GPT-3.5 scores approximately 88. GPT-4o scores approximately 96.
* **GPQA:** Qwen2.5-72B scores approximately 22. Claude3.5 scores approximately 24. GPT-3.5 scores approximately 18. GPT-4o scores approximately 28.
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:** Qwen2.5-72B scores approximately 86. GPT-4o scores approximately 94. QWQ-32B scores approximately 88. DeepSeekV3 scores approximately 82.
* **GSM8k:** Qwen2.5-72B scores approximately 84. GPT-4o scores approximately 92. QWQ-32B scores approximately 86. DeepSeekV3 scores approximately 78.
* **GPQA:** Qwen2.5-72B scores approximately 14. GPT-4o scores approximately 10. QWQ-32B scores approximately 12. DeepSeekV3 scores approximately 8.
### Key Observations
* GPT-4o consistently achieves the highest scores across all datasets in the closed-source and instruction-based/reasoning charts.
* Qwen2.5-72B performs well across all datasets, often outperforming other open-source models.
* LLaMA3-1.8B consistently has the lowest scores among the open-source models.
* Performance varies significantly across datasets. Models generally perform better on HotpotQA and GSM8k than on GPQA.
* The gap in performance between open-source and closed-source models is noticeable, with closed-source models generally achieving higher scores.
### Interpretation
The data suggests a clear hierarchy in LLM performance. GPT-4o emerges as the top performer, demonstrating strong capabilities across all evaluated datasets. Qwen2.5-72B represents a strong open-source alternative, often rivaling or exceeding the performance of smaller closed-source models. The significant performance difference between the smaller LLaMA3-1.8B and the larger LLaMA3-70B highlights the importance of model size in achieving higher scores.
The varying performance across datasets indicates that LLM capabilities are not uniform. HotpotQA and GSM8k, which likely involve more factual recall and reasoning, are areas where these models excel compared to GPQA, which may require more complex problem-solving or nuanced understanding.
The comparison between instruction-based and reasoning LLMs (Chart 3) shows that GPT-4o continues to lead, suggesting that its architecture or training data effectively combines both instruction following and reasoning abilities. The relatively lower scores on GPQA across all models in this chart could indicate that this dataset poses a unique challenge for both instruction-based and reasoning approaches.