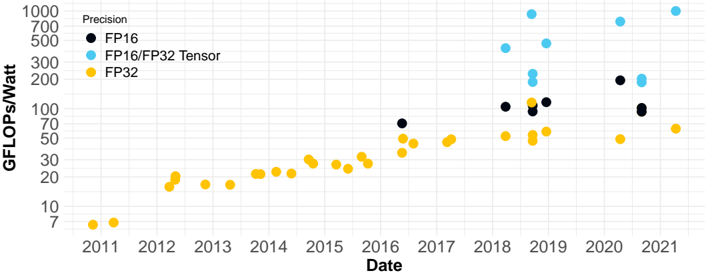
## Line Chart: GFLOPs/Watt Performance Trends (2011-2021)
### Overview
The chart visualizes the evolution of computational efficiency (GFLOPs/Watt) across three precision formats (FP16, FP16/FP32 Tensor, FP32) over a decade. Data points are plotted annually, with distinct color-coded series for each precision type.
### Components/Axes
- **X-axis (Date)**: Years from 2011 to 2021, marked at 1-year intervals.
- **Y-axis (GFLOPs/Watt)**: Logarithmic scale from 7 to 1000, with intervals at 7, 20, 50, 100, 200, 500, and 1000.
- **Legend**: Located in the top-left corner, associating:
- **Black dots**: FP16
- **Blue dots**: FP16/FP32 Tensor
- **Yellow dots**: FP32
### Detailed Analysis
1. **FP32 (Yellow)**:
- **Trend**: Gradual, linear increase from ~7 GFLOPs/Watt in 2011 to ~60 GFLOPs/Watt in 2021.
- **Key Data Points**:
- 2011: ~7 GFLOPs/Watt
- 2015: ~25 GFLOPs/Watt
- 2020: ~50 GFLOPs/Watt
2. **FP16 (Black)**:
- **Trend**: Steeper growth starting in 2016, reaching ~200 GFLOPs/Watt by 2021.
- **Key Data Points**:
- 2016: ~70 GFLOPs/Watt
- 2018: ~100 GFLOPs/Watt
- 2021: ~200 GFLOPs/Watt
3. **FP16/FP32 Tensor (Blue)**:
- **Trend**: Sharp exponential rise beginning in 2018, peaking at ~1000 GFLOPs/Watt in 2021.
- **Key Data Points**:
- 2018: ~200 GFLOPs/Watt
- 2020: ~700 GFLOPs/Watt
- 2021: ~1000 GFLOPs/Watt
### Key Observations
- **FP32 Baseline**: Consistent but slow improvement, reflecting legacy hardware limitations.
- **FP16 Acceleration**: Doubles efficiency every ~3 years post-2016, aligning with GPU advancements (e.g., NVIDIA Volta/Ampere architectures).
- **Tensor Leap**: The FP16/FP32 Tensor series dominates post-2018, suggesting specialized hardware (e.g., tensor cores) for AI/ML workloads.
- **Anomalies**: No data points for FP16/FP32 Tensor before 2018, indicating its emergence as a novel technology.
### Interpretation
The data underscores a paradigm shift in computational efficiency driven by precision optimization and specialized hardware. The FP16/FP32 Tensor series’ exponential growth (2018–2021) likely reflects innovations like NVIDIA’s Tensor Cores, which accelerate matrix operations critical for deep learning. FP16’s rise highlights the industry’s pivot toward lower-precision computing for performance gains, while FP32 remains a stable but outdated benchmark. The absence of pre-2018 Tensor data suggests its adoption coincided with the rise of AI-driven workloads, marking a turning point in hardware design priorities.