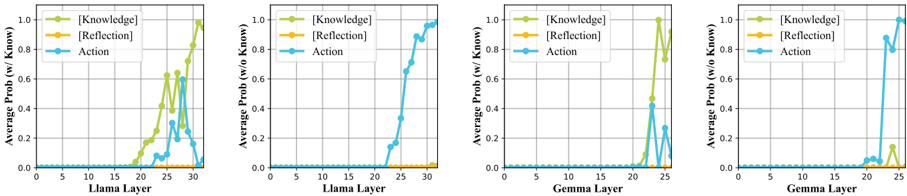
## Line Chart: Average Probability vs. Layer
### Overview
The image presents four line charts, each depicting the average probability of "Knowledge", "Reflection", and "Action" as a function of layer number within a neural network. Two charts focus on the "Llama" model, and two on the "Gemma" model. Each chart is labeled with whether the probability is calculated "w/ Know" (with knowledge) or "w/o Know" (without knowledge). The charts visually represent how the activation of these concepts changes as information propagates through the layers of the respective models.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Layer" - ranging from 0 to approximately 35 for Llama charts and 0 to 25 for Gemma charts. The axis is labeled with numerical markers at intervals of 5.
* **Y-axis:** "Average Prob (w/ Know)" or "Average Prob (w/o Know)" - ranging from 0.0 to 1.0. The axis is labeled with numerical markers at intervals of 0.2.
* **Legend:** Located in the top-right corner of each chart. It defines the color-coding for the three concepts:
* Knowledge: Green line with triangle markers.
* Reflection: Yellow line with circle markers.
* Action: Blue line with square markers.
### Detailed Analysis or Content Details
**Chart 1: Llama (w/ Know)**
* **Action (Blue):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 18, then rapidly increases to approximately 1.0 by layer 35.
* **Reflection (Yellow):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 18, then increases to approximately 0.6 by layer 35.
* **Knowledge (Green):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 20, then rapidly increases to approximately 1.0 by layer 35.
**Chart 2: Llama (w/o Know)**
* **Action (Blue):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 20, then increases to approximately 0.8 by layer 35.
* **Reflection (Yellow):** The line starts at approximately 0.0 at layer 0, remains near 0.0 throughout the entire range of layers.
* **Knowledge (Green):** The line starts at approximately 0.0 at layer 0, remains near 0.0 throughout the entire range of layers.
**Chart 3: Gemma (w/ Know)**
* **Action (Blue):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 20, then rapidly increases to approximately 1.0 by layer 25.
* **Reflection (Yellow):** The line starts at approximately 0.0 at layer 0, increases to approximately 0.8 by layer 20, then decreases slightly to approximately 0.7 by layer 25.
* **Knowledge (Green):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 22, then rapidly increases to approximately 1.0 by layer 25.
**Chart 4: Gemma (w/o Know)**
* **Action (Blue):** The line starts at approximately 0.0 at layer 0, remains near 0.0 until layer 15, then increases to approximately 0.6 by layer 25.
* **Reflection (Yellow):** The line starts at approximately 0.0 at layer 0, remains near 0.0 throughout the entire range of layers.
* **Knowledge (Green):** The line starts at approximately 0.0 at layer 0, remains near 0.0 throughout the entire range of layers.
### Key Observations
* For both Llama and Gemma, the "Action" and "Knowledge" probabilities increase significantly in the later layers when "w/ Know" is used.
* "Reflection" shows a more moderate increase in probability, peaking around layer 20 for Gemma (w/ Know).
* When "w/o Know" is used, the "Action" probability still increases, but to a lesser extent. "Reflection" and "Knowledge" remain consistently low.
* The transition point where probabilities begin to increase appears to be later for Llama than for Gemma.
### Interpretation
The data suggests that the concepts of "Knowledge" and "Action" are learned and activated in the deeper layers of both the Llama and Gemma models, particularly when the models are provided with knowledge ("w/ Know"). The relatively low probabilities of "Reflection" and "Knowledge" when knowledge is *not* provided ("w/o Know") indicates that these concepts are heavily reliant on external knowledge input.
The difference in the transition point between Llama and Gemma suggests that these models may have different architectures or training procedures that affect how quickly they learn and activate these concepts. The steeper increase in probabilities for Llama (w/ Know) compared to Gemma (w/ Know) could indicate that Llama is more sensitive to the presence of knowledge.
The consistent low probability of "Reflection" across all conditions suggests that this concept is either less prominent in these models or requires a different type of activation than the one being measured. The data highlights the importance of knowledge input for activating higher-level cognitive concepts like "Knowledge" and "Action" within these large language models.