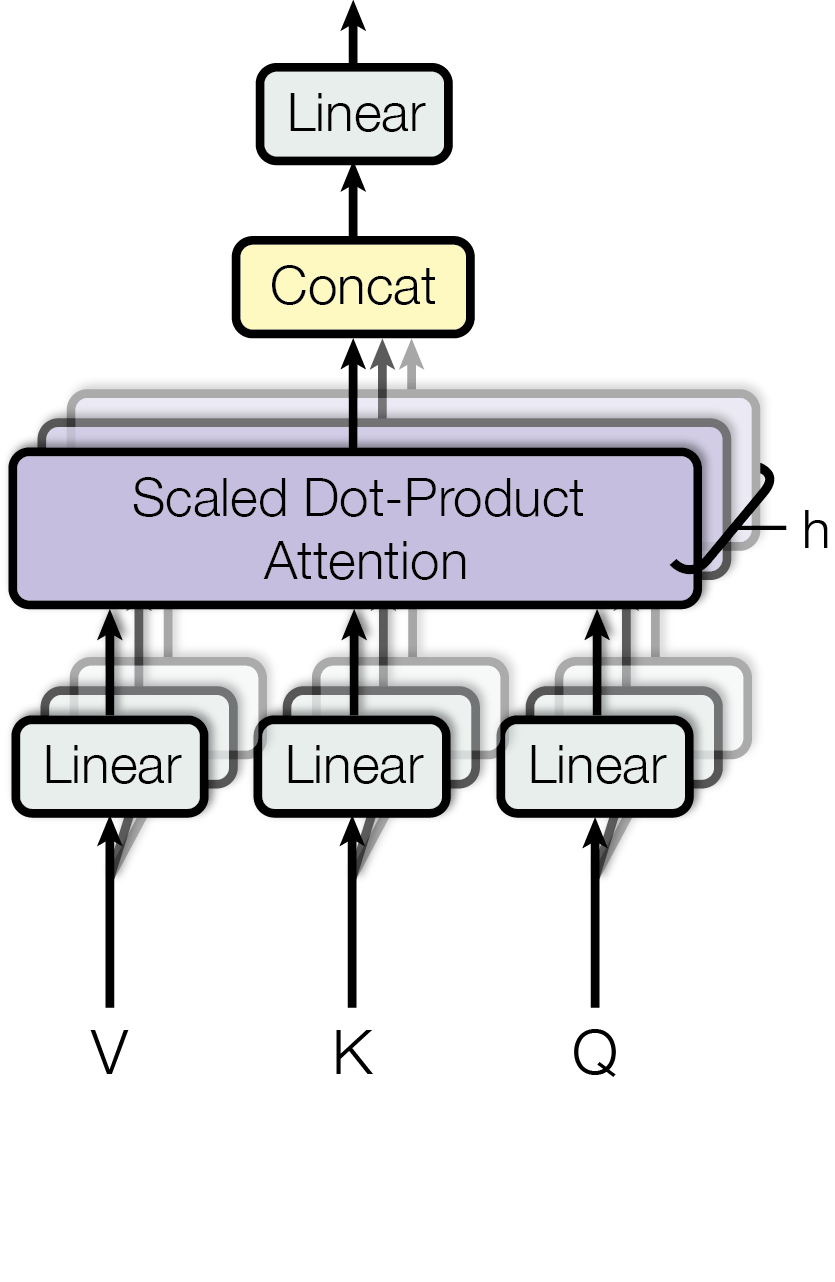
## Diagram: Multi-Head Attention Mechanism
### Overview
The image is a vertical flowchart diagram illustrating the architecture of the "Multi-Head Attention" mechanism, a key component in Transformer neural networks. It depicts the flow of data from three input vectors (V, K, Q) through multiple parallel processing layers ("heads"), followed by concatenation and a final linear projection.
### Components & Flow Analysis
#### 1. Input Layer (Bottom)
* **Inputs:** Three distinct inputs are positioned at the bottom of the diagram, labeled with single capital letters.
* **V** (Left) - Represents "Values"
* **K** (Center) - Represents "Keys"
* **Q** (Right) - Represents "Queries"
* **Flow:** Each input has a black arrow pointing vertically upward, leading into the first processing stage.
#### 2. Linear Projection Layer (Lower)
* **Structure:** There are three rectangular boxes labeled "Linear" arranged horizontally.
* **Stacking:** Behind each visible "Linear" box, there are faint, shadowed outlines of identical boxes, indicating that this operation happens multiple times in parallel.
* **Connections:**
* Input **V** connects to the left "Linear" stack.
* Input **K** connects to the center "Linear" stack.
* Input **Q** connects to the right "Linear" stack.
#### 3. Attention Layer (Middle)
* **Label:** A large, wide purple rectangle is labeled:
* "Scaled Dot-Product" (top line)
* "Attention" (bottom line)
* **Stacking:** Similar to the Linear layer below, this box has multiple shadowed copies stacked behind it, visually representing depth.
* **Annotation:** A bracket on the right side of this stack encompasses the depth and is labeled with the letter **"h"**. This explicitly denotes that there are *h* number of parallel attention layers (heads).
* **Connections:** The outputs from the three lower "Linear" stacks feed directly into this "Scaled Dot-Product Attention" stack.
#### 4. Concatenation Layer (Upper Middle)
* **Label:** A yellow rectangle with rounded corners is labeled **"Concat"**.
* **Flow:** Multiple arrows emerge from the top of the "Scaled Dot-Product Attention" stack and converge into this single box. This represents the outputs of all *h* heads being joined together.
#### 5. Final Linear Projection (Top)
* **Label:** A final rectangular box labeled **"Linear"**.
* **Flow:** A single arrow points upward from the "Concat" box into this final "Linear" layer.
* **Output:** A final arrow points vertically upward from this box, representing the final output of the Multi-Head Attention block.
### Content Details (Text Transcription)
* **Inputs:** "V", "K", "Q"
* **Lower Blocks:** "Linear", "Linear", "Linear"
* **Middle Block:** "Scaled Dot-Product Attention"
* **Variable:** "h" (indicating the number of heads)
* **Upper Middle Block:** "Concat"
* **Top Block:** "Linear"
### Key Observations
* **Parallelism:** The diagram heavily emphasizes parallel processing through the visual metaphor of stacked boxes (shadows) and the "h" label. This indicates that the V, K, and Q inputs are split and processed independently multiple times before being recombined.
* **Color Coding:**
* **Grey/White:** Linear projection layers.
* **Purple:** The core Attention mechanism.
* **Yellow:** The Concatenation operation.
* **Symmetry:** The input stage is perfectly symmetrical, treating V, K, and Q with identical initial linear transformations.
### Interpretation
This diagram describes the **Multi-Head Attention** sub-layer defined in the seminal paper "Attention Is All You Need" (Vaswani et al., 2017).
1. **Function:** It allows the model to jointly attend to information from different representation subspaces at different positions. A single attention head might focus on one aspect of the relationship between words (e.g., subject-verb agreement), while another head focuses on a different aspect (e.g., temporal relationship).
2. **Process:**
* The inputs (Queries, Keys, Values) are first projected linearly $h$ times with different, learned linear projections to $d_k$, $d_k$ and $d_v$ dimensions, respectively.
* On each of these projected versions of queries, keys, and values, the attention function is performed in parallel.
* These are the $h$ outputs (the "heads").
* These outputs are concatenated and once again projected, resulting in the final values.
3. **Significance of "h":** The label "h" is crucial. It signifies the hyperparameter for the number of heads. In the original Transformer base model, $h=8$. This design improves the model's ability to focus on different positions, giving the attention layer multiple "representation subspaces."