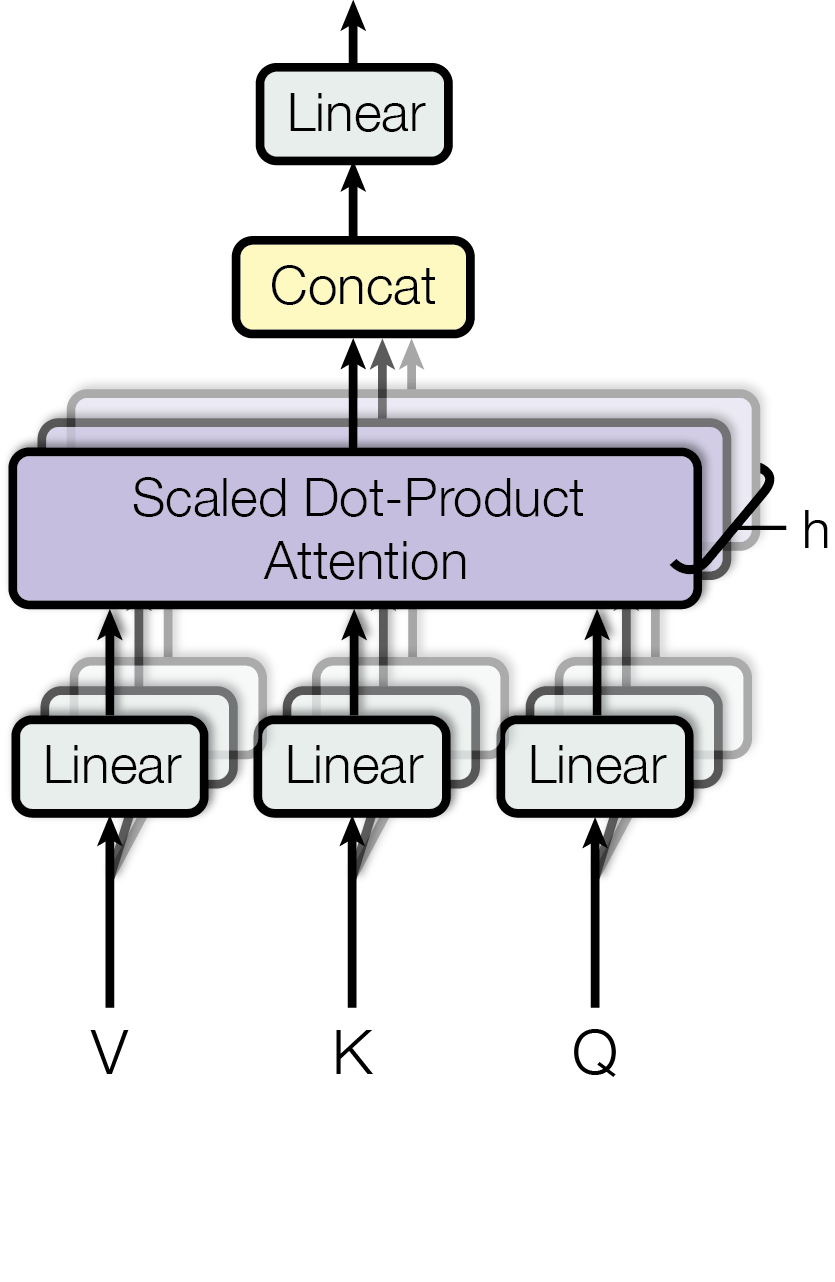
## Diagram: Scaled Dot-Product Attention Mechanism
### Overview
The image is a diagram illustrating the Scaled Dot-Product Attention mechanism, a key component in transformer models. It shows the flow of data through linear transformations, the attention calculation, concatenation, and a final linear transformation.
### Components/Axes
* **Input Layers (Bottom):**
* V (Value): Input to a "Linear" transformation.
* K (Key): Input to a "Linear" transformation.
* Q (Query): Input to a "Linear" transformation.
* **Linear Transformations:** Three "Linear" blocks, each receiving input from V, K, and Q respectively.
* **Scaled Dot-Product Attention:** A central, larger block labeled "Scaled Dot-Product Attention". It receives input from the three "Linear" blocks.
* **Output from Attention:** An arrow labeled "h" exits from the right side of the "Scaled Dot-Product Attention" block.
* **Concat:** A block labeled "Concat" receives input from the "Scaled Dot-Product Attention" block.
* **Output Layer (Top):** A "Linear" block receives input from the "Concat" block.
* **Arrows:** Arrows indicate the direction of data flow between the components.
### Detailed Analysis
1. **Input:** The diagram starts with three inputs: V (Value), K (Key), and Q (Query).
2. **Linear Transformations:** Each input (V, K, Q) is passed through a "Linear" transformation. These transformations are represented by rectangular blocks with rounded corners.
3. **Scaled Dot-Product Attention:** The outputs of the three "Linear" transformations are fed into the "Scaled Dot-Product Attention" block. This block calculates the attention weights based on the dot product of the query and keys, scaled by the dimension of the keys.
4. **Output from Attention:** The output from the "Scaled Dot-Product Attention" block is labeled "h".
5. **Concatenation:** The output from the "Scaled Dot-Product Attention" block is then passed to a "Concat" block, where the attention outputs are concatenated.
6. **Final Linear Transformation:** The concatenated output is passed through a final "Linear" transformation.
7. **Data Flow:** The arrows indicate the flow of data from the inputs, through the transformations, to the final output.
### Key Observations
* The diagram clearly illustrates the sequence of operations in the Scaled Dot-Product Attention mechanism.
* The use of "Linear" transformations before and after the attention calculation is highlighted.
* The "Concat" block suggests that multiple attention heads might be used, and their outputs are concatenated.
### Interpretation
The diagram represents the Scaled Dot-Product Attention mechanism, a core component of the Transformer architecture. The mechanism computes attention weights by taking the dot product of the query (Q) with all keys (K), scaling the result, and then applying a softmax function to obtain the weights on the values (V). The "Linear" transformations before and after the attention calculation allow the model to learn different representations of the input data. The concatenation step suggests the use of multi-head attention, where the attention mechanism is applied multiple times in parallel with different learned linear projections, and the results are concatenated to capture different aspects of the input. The final "Linear" transformation projects the concatenated output to the desired output dimension. The output "h" represents the context-aware representation learned by the attention mechanism.