\n
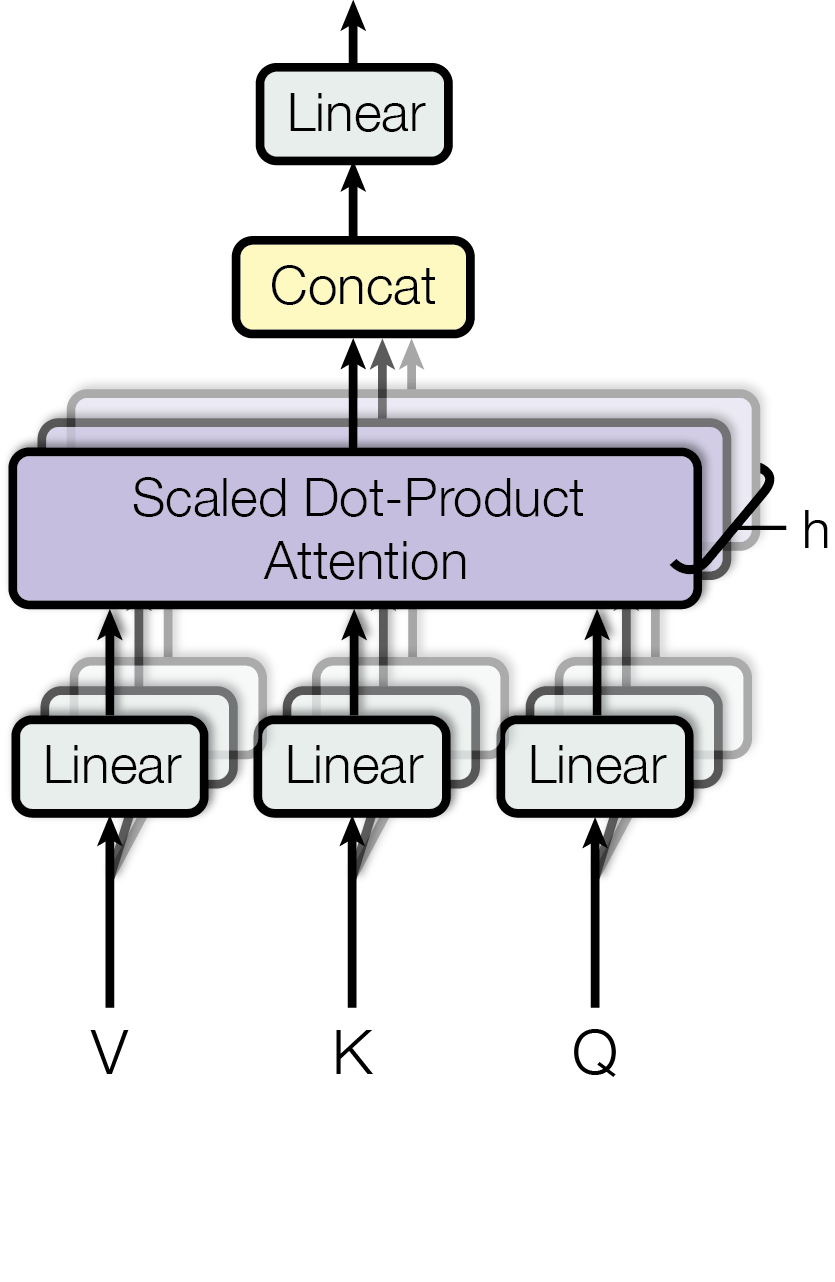
## Diagram: Scaled Dot-Product Attention Mechanism
### Overview
The image depicts a diagram illustrating the Scaled Dot-Product Attention mechanism, a core component of the Transformer architecture used in natural language processing and other machine learning tasks. The diagram shows the flow of data through several linear transformations and the attention layer itself.
### Components/Axes
The diagram consists of the following components:
* **Inputs:** V, K, Q (representing Value, Key, and Query respectively)
* **Linear Transformations:** Three "Linear" blocks taking Q, K, and V as inputs.
* **Scaled Dot-Product Attention:** A large purple block labeled "Scaled Dot-Product Attention".
* **Concat:** A yellow block labeled "Concat".
* **Output Linear Transformation:** A "Linear" block at the top of the diagram.
* **h:** A label with the value 'h' attached to the right side of the Scaled Dot-Product Attention block.
The diagram uses arrows to indicate the flow of data between these components.
### Detailed Analysis or Content Details
The diagram shows a sequential flow of operations:
1. **Inputs:** The process begins with three inputs: V, K, and Q.
2. **Linear Transformations:** Each input (V, K, Q) is passed through a separate "Linear" transformation block.
3. **Scaled Dot-Product Attention:** The outputs of the three "Linear" blocks are fed into the "Scaled Dot-Product Attention" block.
4. **Concatenation:** The output of the "Scaled Dot-Product Attention" block is then passed to a "Concat" block.
5. **Output Linear Transformation:** Finally, the output of the "Concat" block is passed through another "Linear" transformation block to produce the final output.
6. **h:** The label 'h' is positioned on the right side of the Scaled Dot-Product Attention block, potentially indicating a hyperparameter or dimension related to the attention mechanism.
The arrows indicate a unidirectional flow of information from bottom to top. The arrows connecting the "Linear" blocks to the "Scaled Dot-Product Attention" block are gray. The arrow connecting the "Scaled Dot-Product Attention" block to the "Concat" block is also gray. The arrow connecting the "Concat" block to the final "Linear" block is also gray.
### Key Observations
The diagram illustrates a clear sequence of operations, highlighting the key steps involved in the Scaled Dot-Product Attention mechanism. The use of "Linear" transformations suggests that the inputs are being projected into different spaces before being used in the attention calculation. The "Concat" block likely combines the outputs of the attention mechanism in some way.
### Interpretation
This diagram represents a simplified view of the Scaled Dot-Product Attention mechanism. The attention mechanism is a crucial component of the Transformer architecture, enabling the model to focus on different parts of the input sequence when making predictions. The "Scaled Dot-Product Attention" block performs the core attention calculation, while the "Linear" transformations and "Concat" block prepare the inputs and combine the outputs. The 'h' label likely represents the number of attention heads, a key parameter in the Transformer architecture. The diagram effectively conveys the flow of information and the key components involved in this important machine learning technique. The diagram does not provide any numerical data or specific parameter values, but rather focuses on the structural relationships between the components.