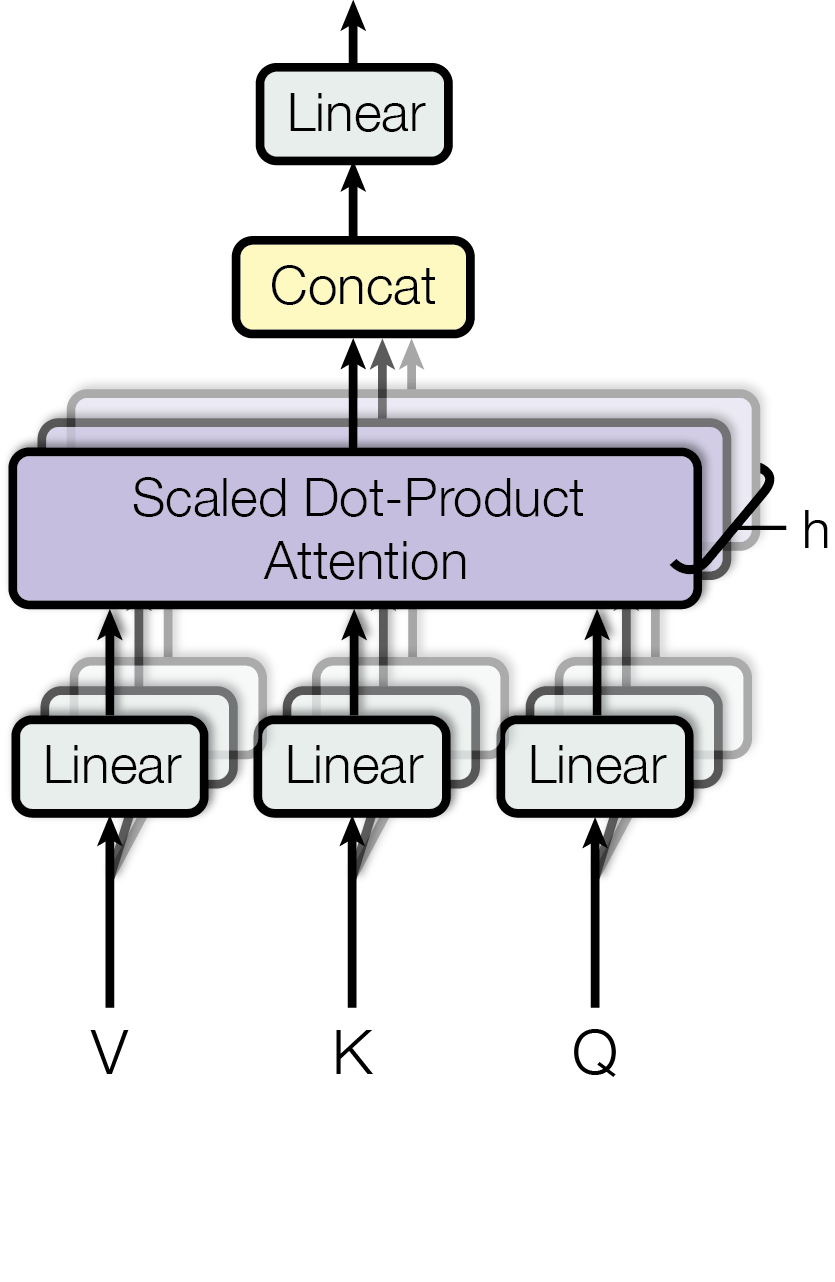
# Technical Diagram Analysis: Scaled Dot-Product Attention Mechanism
## Diagram Structure
The image depicts a computational flow diagram of a **Scaled Dot-Product Attention** mechanism, a core component in transformer architectures. The diagram uses color-coded blocks and directional arrows to represent data flow and operations.
---
### Key Components & Labels
1. **Input Vectors**
- Three parallel **Linear** layers (light blue blocks) labeled:
- `V` (Value)
- `K` (Key)
- `Q` (Query)
- These represent the input embeddings transformed into value, key, and query vectors.
2. **Concatenation**
- A **Concat** block (yellow) receives outputs from the three linear layers.
- Function: Combines the transformed `V`, `K`, and `Q` vectors into a single tensor.
3. **Scaled Dot-Product Attention**
- A **Scaled Dot-Product Attention** block (purple) processes the concatenated tensor.
- Output: A tensor labeled `h` (highlighted with a black arrow pointing right).
---
### Data Flow
1. **Bottom-Up Flow**
- `V`, `K`, and `Q` vectors pass through their respective **Linear** layers.
- Outputs are concatenated into a single tensor.
2. **Attention Computation**
- The concatenated tensor is fed into the **Scaled Dot-Product Attention** block.
- The block computes attention scores via dot-products of queries and keys, scales them, and applies softmax to derive weights.
- These weights are applied to the value vectors to produce the final output `h`.
---
### Color Coding & Spatial Grounding
- **Colors**:
- Light blue: Linear layers (`V`, `K`, `Q`).
- Yellow: Concatenation block.
- Purple: Scaled Dot-Product Attention block.
- Black: Arrows (data flow) and output label `h`.
- **Spatial Layout**:
- Inputs (`V`, `K`, `Q`) are positioned at the bottom.
- Concatenation is centered above the inputs.
- Attention block is positioned above concatenation.
- Output `h` branches to the right of the attention block.
---
### Notes
- No numerical data, trends, or legends are present in the diagram.
- The diagram focuses on architectural components rather than quantitative analysis.
- All labels and operations are explicitly annotated in English.
This diagram illustrates the standard attention mechanism used in transformers, emphasizing the flow from input embeddings to the final output tensor `h`.