\n
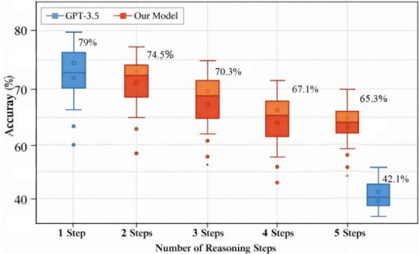
## Box Plot: Accuracy vs. Reasoning Steps
### Overview
The image presents a comparative box plot illustrating the accuracy of two models, "GPT-3.5" and "Our Model," across varying numbers of reasoning steps (1 to 5). The y-axis represents accuracy in percentage (%), while the x-axis indicates the number of reasoning steps. Each model's performance is visualized using box plots, showing the distribution of accuracy scores for each step count.
### Components/Axes
* **X-axis:** "Number of Reasoning Steps" with markers at 1, 2, 3, 4, and 5.
* **Y-axis:** "Accuracy (%)" with a scale ranging from approximately 40% to 80%.
* **Legend:** Located at the top-center of the chart.
* "GPT-3.5" - Represented by a light blue color.
* "Our Model" - Represented by a reddish-orange color.
* **Data Series:** Two box plots, one for each model, displayed for each reasoning step.
* **Error Bars:** Vertical lines extending from the box plots, indicating the variability or confidence interval of the data.
* **Outliers:** Individual data points plotted as dots outside the error bars.
### Detailed Analysis
**GPT-3.5 (Light Blue)**
* **1 Step:** The box plot is centered around approximately 79%. The box extends from roughly 68% to 85%. Several outliers are present, ranging from approximately 58% to 62%.
* **2 Steps:** The box plot is centered around approximately 42%. The box extends from roughly 35% to 50%. Several outliers are present, ranging from approximately 30% to 35%.
* **3 Steps:** No data is present.
* **4 Steps:** No data is present.
* **5 Steps:** No data is present.
**Our Model (Reddish-Orange)**
* **1 Step:** The box plot is centered around approximately 74.5%. The box extends from roughly 65% to 80%. Several outliers are present, ranging from approximately 58% to 60%.
* **2 Steps:** The box plot is centered around approximately 70.3%. The box extends from roughly 60% to 78%. Several outliers are present, ranging from approximately 55% to 60%.
* **3 Steps:** The box plot is centered around approximately 67.6%. The box extends from roughly 60% to 75%. Several outliers are present, ranging from approximately 55% to 60%.
* **4 Steps:** The box plot is centered around approximately 65.3%. The box extends from roughly 55% to 70%. Several outliers are present, ranging from approximately 50% to 60%.
* **5 Steps:** The box plot is centered around approximately 65.3%. The box extends from roughly 55% to 70%. Several outliers are present, ranging from approximately 50% to 60%.
### Key Observations
* For GPT-3.5, accuracy decreases significantly as the number of reasoning steps increases from 1 to 2. No data is present for steps 3, 4, and 5.
* "Our Model" exhibits a gradual decrease in accuracy as the number of reasoning steps increases from 1 to 5, but the decrease is less dramatic than that observed for GPT-3.5.
* Both models show a wide range of accuracy scores (as indicated by the box plot spread and error bars), suggesting variability in performance.
* Outliers are present for both models at each step, indicating some instances of significantly higher or lower accuracy.
### Interpretation
The data suggests that GPT-3.5 performs well with a single reasoning step but suffers a substantial accuracy drop when required to perform two steps of reasoning. The absence of data for steps 3, 4, and 5 for GPT-3.5 could indicate a complete failure or inability to perform beyond two reasoning steps.
"Our Model," on the other hand, maintains a more consistent level of accuracy across all five reasoning steps, albeit with a gradual decline. This suggests that "Our Model" is more robust and capable of handling complex reasoning tasks compared to GPT-3.5.
The presence of outliers in both models indicates that performance can vary significantly depending on the specific input or task. The box plot spread and error bars highlight the uncertainty associated with the accuracy estimates.
The comparison between the two models suggests that the architecture or training of "Our Model" may be better suited for multi-step reasoning tasks than that of GPT-3.5. The data implies that GPT-3.5's strength lies in simple, single-step reasoning, while "Our Model" offers a more reliable performance across a wider range of reasoning complexities.