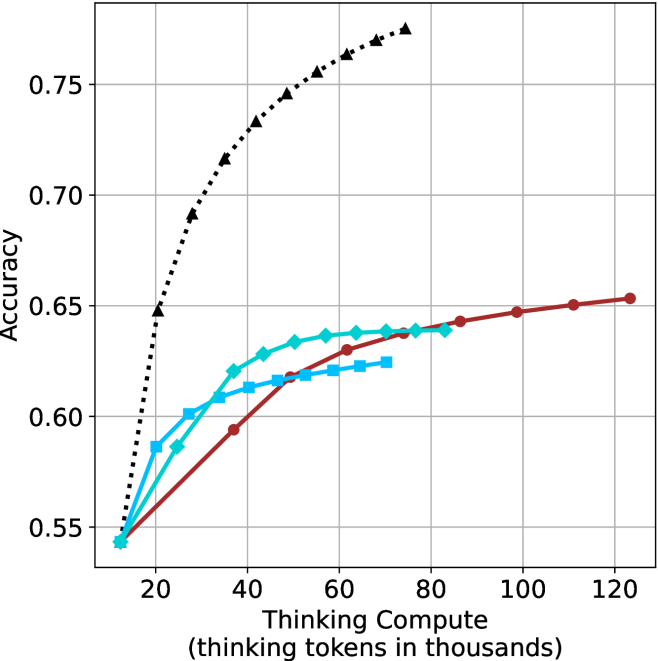
## Line Chart: Accuracy vs. Thinking Compute (Tokens in Thousands)
### Overview
The chart compares the accuracy of three computational models as a function of "Thinking Compute" (measured in thousands of thinking tokens). Three data series are plotted:
1. **Black dotted line**: "Thinking Compute"
2. **Blue dashed line**: "Thinking Compute + Chain of Thought"
3. **Red solid line**: "Thinking Compute + Chain of Thought + Self-Consistency"
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)"
- Scale: 20 to 120 (increments of 20)
- **Y-axis**: "Accuracy"
- Scale: 0.55 to 0.75 (increments of 0.05)
- **Legend**: Located on the right, associating colors with models:
- Black: "Thinking Compute"
- Blue: "Thinking Compute + Chain of Thought"
- Red: "Thinking Compute + Chain of Thought + Self-Consistency"
### Detailed Analysis
1. **Black Dotted Line ("Thinking Compute")**:
- Starts at (20k tokens, 0.65 accuracy).
- Rises sharply to (80k tokens, 0.75 accuracy), then plateaus.
- Key points:
- 40k tokens: ~0.70 accuracy
- 60k tokens: ~0.73 accuracy
- 100k tokens: ~0.75 accuracy
2. **Blue Dashed Line ("Thinking Compute + Chain of Thought")**:
- Starts at (20k tokens, 0.58 accuracy).
- Gradually increases to (80k tokens, 0.64 accuracy), then plateaus.
- Key points:
- 40k tokens: ~0.62 accuracy
- 60k tokens: ~0.63 accuracy
- 100k tokens: ~0.64 accuracy
3. **Red Solid Line ("Thinking Compute + Chain of Thought + Self-Consistency")**:
- Starts at (20k tokens, 0.55 accuracy).
- Steady increase to (100k tokens, 0.65 accuracy), then plateaus.
- Key points:
- 40k tokens: ~0.60 accuracy
- 60k tokens: ~0.62 accuracy
- 120k tokens: ~0.65 accuracy
### Key Observations
- **Highest Accuracy**: The "Thinking Compute" model (black) achieves the highest plateau (~0.75 accuracy) but requires fewer tokens (80k) to reach saturation.
- **Diminishing Returns**: All models show diminishing returns after ~80k tokens, with accuracy gains slowing or stopping.
- **Model Complexity Tradeoff**:
- Adding "Chain of Thought" (blue) improves accuracy by ~0.06 over baseline (black) at 80k tokens.
- Adding "Self-Consistency" (red) further improves accuracy by ~0.01 over blue at 100k tokens.
- **Initial Performance Gap**: At 20k tokens, "Thinking Compute" already outperforms the other models by ~0.07 accuracy.
### Interpretation
The data suggests that **raw "Thinking Compute" alone is the most efficient** for achieving high accuracy, outperforming models with added reasoning strategies (Chain of Thought, Self-Consistency) even at lower token counts. However, the inclusion of reasoning strategies still provides incremental gains, albeit with diminishing returns.
- **Why It Matters**:
- For resource-constrained systems, prioritizing "Thinking Compute" may yield better results than complex reasoning pipelines.
- The plateau at ~80k tokens for "Thinking Compute" implies that beyond this point, additional tokens do not significantly improve accuracy.
- **Anomalies**:
- The red line (most complex model) starts with the lowest accuracy at 20k tokens but catches up to blue by 80k tokens. This suggests that self-consistency may require more tokens to manifest its benefits.
- The black line’s sharp initial rise indicates that "Thinking Compute" has a strong foundational impact, while reasoning strategies add value primarily at scale.
This analysis highlights a tradeoff between computational efficiency and model complexity, with implications for optimizing AI systems in token-limited environments.