## [Bar Charts]: VRAM Usage and Average Accuracy vs. Model Parameter Count
### Overview
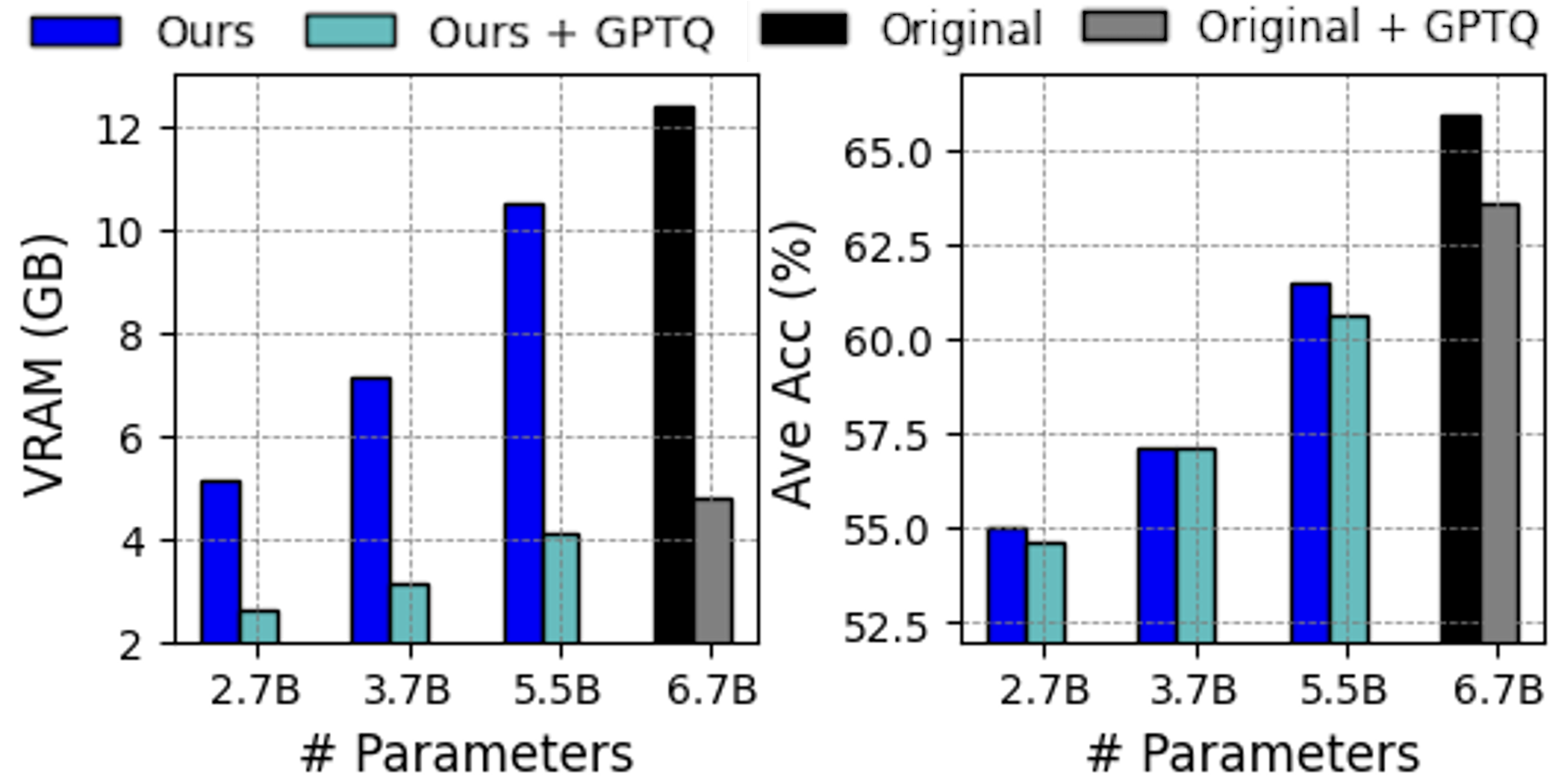
The image displays two side-by-side bar charts comparing the performance of different model variants across four model sizes (2.7B, 3.7B, 5.5B, and 6.7B parameters). The left chart measures Video RAM (VRAM) usage in Gigabytes (GB), and the right chart measures Average Accuracy (Ave Acc) as a percentage. The comparison involves four model configurations: "Ours," "Ours + GPTQ," "Original," and "Original + GPTQ."
### Components/Axes
* **Legend (Top-Center, spanning both charts):**
* **Blue Bar:** "Ours"
* **Teal Bar:** "Ours + GPTQ"
* **Black Bar:** "Original"
* **Gray Bar:** "Original + GPTQ"
* **Left Chart - VRAM (GB):**
* **Y-axis:** Label: "VRAM (GB)". Scale: 2 to 12, with major ticks every 2 units.
* **X-axis:** Label: "# Parameters". Categories: "2.7B", "3.7B", "5.5B", "6.7B".
* **Right Chart - Ave Acc (%):**
* **Y-axis:** Label: "Ave Acc (%)". Scale: 52.5 to 65.0, with major ticks every 2.5 units.
* **X-axis:** Label: "# Parameters". Categories: "2.7B", "3.7B", "5.5B", "6.7B".
### Detailed Analysis
**Left Chart: VRAM (GB)**
* **Trend Verification:** For the "Ours" (blue) and "Ours + GPTQ" (teal) series, VRAM usage increases with the number of parameters. The "Original" (black) and "Original + GPTQ" (gray) series are only present for the 6.7B parameter model.
* **Data Points (Approximate Values):**
* **2.7B Parameters:**
* Ours (Blue): ~5.2 GB
* Ours + GPTQ (Teal): ~2.6 GB
* **3.7B Parameters:**
* Ours (Blue): ~7.1 GB
* Ours + GPTQ (Teal): ~3.1 GB
* **5.5B Parameters:**
* Ours (Blue): ~10.5 GB
* Ours + GPTQ (Teal): ~4.1 GB
* **6.7B Parameters:**
* Original (Black): ~12.4 GB
* Original + GPTQ (Gray): ~4.8 GB
**Right Chart: Ave Acc (%)**
* **Trend Verification:** For all series, average accuracy generally increases with the number of parameters. The "Ours" and "Ours + GPTQ" bars are very close in height for each parameter size, indicating minimal accuracy difference.
* **Data Points (Approximate Values):**
* **2.7B Parameters:**
* Ours (Blue): ~55.0%
* Ours + GPTQ (Teal): ~54.6%
* **3.7B Parameters:**
* Ours (Blue): ~57.2%
* Ours + GPTQ (Teal): ~57.2%
* **5.5B Parameters:**
* Ours (Blue): ~61.5%
* Ours + GPTQ (Teal): ~60.7%
* **6.7B Parameters:**
* Original (Black): ~66.0%
* Original + GPTQ (Gray): ~63.5%
### Key Observations
1. **VRAM Reduction with GPTQ:** Applying GPTQ quantization ("Ours + GPTQ" vs. "Ours", and "Original + GPTQ" vs. "Original") results in a dramatic reduction in VRAM usage across all model sizes. The reduction is most pronounced for the 6.7B model, where VRAM drops from ~12.4 GB to ~4.8 GB.
2. **Accuracy Impact of GPTQ:** The impact of GPTQ on average accuracy is minimal for the "Ours" models (a difference of less than ~1% for 2.7B and 5.5B, and no difference for 3.7B). For the 6.7B "Original" model, GPTQ causes a more noticeable accuracy drop of approximately 2.5 percentage points.
3. **Model Comparison at 6.7B:** At the largest parameter size (6.7B), the "Original" model achieves the highest accuracy (~66.0%) but also requires the most VRAM (~12.4 GB). The "Original + GPTQ" variant offers a significant memory saving (~4.8 GB) with a moderate accuracy trade-off (~63.5%).
4. **Scaling Trend:** Both VRAM usage and average accuracy scale positively with the number of parameters for all model configurations.
### Interpretation
This data demonstrates the trade-offs between model size, memory efficiency, and performance. The primary finding is the effectiveness of GPTQ quantization in drastically reducing VRAM requirements (by more than 50% in most cases) with a relatively small cost to accuracy, especially for the "Ours" model architecture. This suggests that the "Ours" method may be more robust to quantization than the "Original" method at the 6.7B scale.
The charts are likely from a research paper or technical report aiming to showcase a new model architecture ("Ours") and its compatibility with post-training quantization techniques like GPTQ. The key message is that one can deploy larger, more accurate models (like the 6.7B variant) within practical memory constraints by applying GPTQ, making advanced AI models more accessible for deployment on consumer or edge hardware. The absence of "Original" data for smaller models implies the study's focus is on comparing the two architectures at the largest scale or that "Ours" is a new method being proposed for these model sizes.