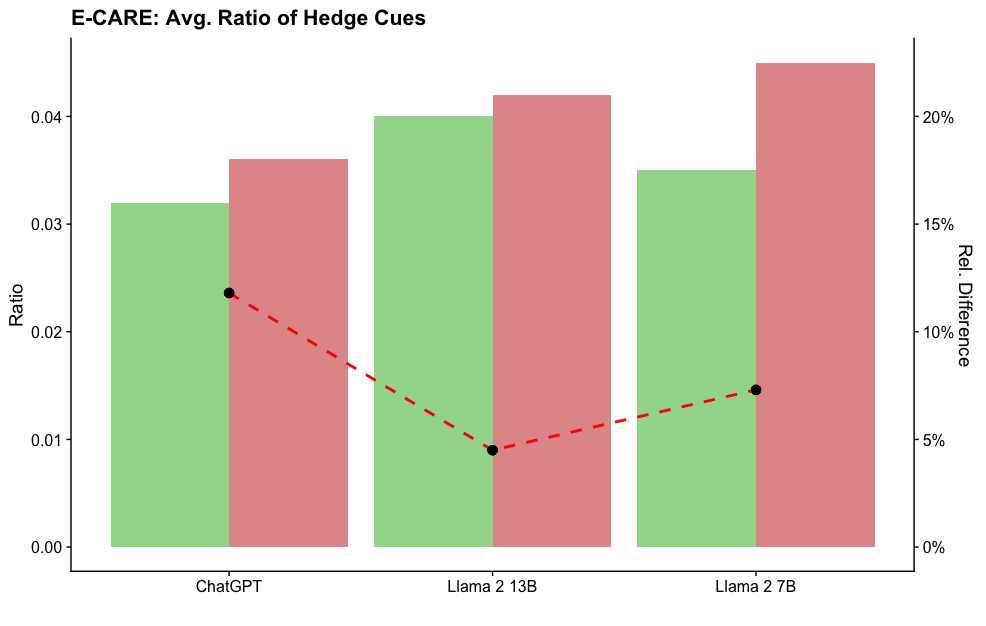
## Bar and Line Chart: E-CARE: Avg. Ratio of Hedge Cues
### Overview
The image is a combination bar and line chart comparing the average ratio of hedge cues for three language models: ChatGPT, Llama 2 13B, and Llama 2 7B. The chart displays two sets of data: the ratio of hedge cues (represented by green bars) and the relative difference (represented by red bars and a dashed red line).
### Components/Axes
* **Title:** E-CARE: Avg. Ratio of Hedge Cues
* **X-axis:** Categorical axis representing the language models: ChatGPT, Llama 2 13B, Llama 2 7B.
* **Left Y-axis:** "Ratio", ranging from 0.00 to 0.04, with increments of 0.01.
* **Right Y-axis:** "Rel. Difference", ranging from 0% to 20%, with increments of 5%.
* **Data Series 1:** Ratio of Hedge Cues (Green Bars)
* **Data Series 2:** Relative Difference (Red Bars and Dashed Red Line)
### Detailed Analysis
* **ChatGPT:**
* Ratio of Hedge Cues (Green Bar): Approximately 0.032
* Relative Difference (Red Bar): Approximately 0.036
* Relative Difference (Red Line): Approximately 12%
* **Llama 2 13B:**
* Ratio of Hedge Cues (Green Bar): Approximately 0.040
* Relative Difference (Red Bar): Approximately 0.042
* Relative Difference (Red Line): Approximately 4%
* **Llama 2 7B:**
* Ratio of Hedge Cues (Green Bar): Approximately 0.035
* Relative Difference (Red Bar): Approximately 0.045
* Relative Difference (Red Line): Approximately 8%
**Trend Verification:**
* **Ratio of Hedge Cues (Green Bars):** Increases from ChatGPT to Llama 2 13B, then decreases slightly to Llama 2 7B.
* **Relative Difference (Red Bars):** Increases from ChatGPT to Llama 2 7B.
* **Relative Difference (Red Line):** Decreases from ChatGPT to Llama 2 13B, then increases to Llama 2 7B.
### Key Observations
* Llama 2 13B has the highest ratio of hedge cues.
* Llama 2 7B has the highest relative difference.
* The relative difference (red line) shows a decreasing trend from ChatGPT to Llama 2 13B, followed by an increasing trend to Llama 2 7B.
### Interpretation
The chart compares the average ratio of hedge cues for three language models. The green bars represent the ratio of hedge cues, while the red bars and red dashed line represent the relative difference. The data suggests that Llama 2 13B has the highest ratio of hedge cues, while Llama 2 7B has the highest relative difference. The relative difference line shows that the difference between the models is not consistent, with Llama 2 13B having a lower relative difference compared to ChatGPT and Llama 2 7B. This could indicate that Llama 2 13B is more consistent in its use of hedge cues compared to the other two models.