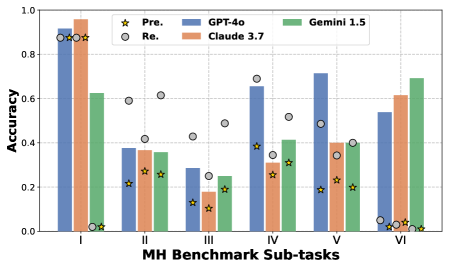
## Bar Chart: MH Benchmark Sub-tasks Accuracy
### Overview
The image is a bar chart comparing the accuracy of different language models (GPT-4o, Claude 3.7, and Gemini 1.5) across six sub-tasks of the MH Benchmark. The chart also includes data points for "Pre." and "Re." which are represented as scatter plots.
### Components/Axes
* **X-axis:** "MH Benchmark Sub-tasks" with categories I, II, III, IV, V, and VI.
* **Y-axis:** "Accuracy" ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located at the top of the chart.
* Yellow Star: "Pre."
* Gray Circle: "Re."
* Blue: "GPT-4o"
* Orange: "Claude 3.7"
* Green: "Gemini 1.5"
### Detailed Analysis
Here's a breakdown of the accuracy for each sub-task and model:
* **Sub-task I:**
* GPT-4o (Blue): Accuracy ~ 0.88
* Claude 3.7 (Orange): Accuracy ~ 0.95
* Gemini 1.5 (Green): Accuracy ~ 0.62
* Pre. (Yellow Star): Accuracy ~ 0.88
* Re. (Gray Circle): Accuracy ~ 0.88
* **Sub-task II:**
* GPT-4o (Blue): Accuracy ~ 0.37
* Claude 3.7 (Orange): Accuracy ~ 0.36
* Gemini 1.5 (Green): Accuracy ~ 0.36
* Pre. (Yellow Star): Accuracy ~ 0.22
* Re. (Gray Circle): Accuracy ~ 0.42
* **Sub-task III:**
* GPT-4o (Blue): Accuracy ~ 0.29
* Claude 3.7 (Orange): Accuracy ~ 0.18
* Gemini 1.5 (Green): Accuracy ~ 0.24
* Pre. (Yellow Star): Accuracy ~ 0.11
* Re. (Gray Circle): Accuracy ~ 0.27
* **Sub-task IV:**
* GPT-4o (Blue): Accuracy ~ 0.35
* Claude 3.7 (Orange): Accuracy ~ 0.41
* Gemini 1.5 (Green): Accuracy ~ 0.31
* Pre. (Yellow Star): Accuracy ~ 0.28
* Re. (Gray Circle): Accuracy ~ 0.50
* **Sub-task V:**
* GPT-4o (Blue): Accuracy ~ 0.72
* Claude 3.7 (Orange): Accuracy ~ 0.40
* Gemini 1.5 (Green): Accuracy ~ 0.39
* Pre. (Yellow Star): Accuracy ~ 0.21
* Re. (Gray Circle): Accuracy ~ 0.49
* **Sub-task VI:**
* GPT-4o (Blue): Accuracy ~ 0.54
* Claude 3.7 (Orange): Accuracy ~ 0.61
* Gemini 1.5 (Green): Accuracy ~ 0.69
* Pre. (Yellow Star): Accuracy ~ 0.03
* Re. (Gray Circle): Accuracy ~ 0.04
### Key Observations
* Claude 3.7 performs best in sub-task I, while Gemini 1.5 performs best in sub-task VI.
* GPT-4o shows the highest accuracy in sub-task V.
* All models have relatively low accuracy in sub-task III.
* The "Pre." values are consistently lower than the model scores, especially in sub-task VI.
* The "Re." values vary across sub-tasks, sometimes exceeding the model scores (e.g., sub-task IV).
### Interpretation
The chart illustrates the varying performance of different language models across different sub-tasks within the MH Benchmark. The differences in accuracy suggest that each model has strengths and weaknesses depending on the specific task. The "Pre." and "Re." data points likely represent baseline or reference scores, indicating the improvement achieved by the language models. The significant difference between "Pre." and model scores in sub-task VI suggests that the models have made substantial progress in this area. The "Re." values, sometimes exceeding model scores, could indicate the presence of a regression or a different evaluation metric.