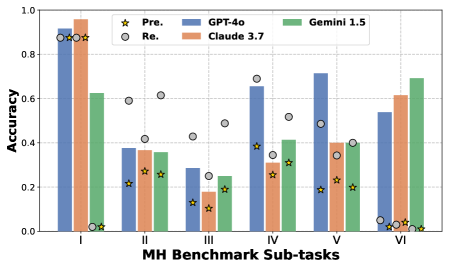
## Bar Chart: MH Benchmark Sub-tasks Accuracy Comparison
### Overview
The chart compares the accuracy of three AI models (GPT-4o, Claude 3.7, Gemini 1.5) across six MH Benchmark sub-tasks (I–VI). It also includes "Pre." (pre-training) and "Re." (retrieval) performance markers. Accuracy ranges from 0.0 to 1.0 on the y-axis.
### Components/Axes
- **X-axis**: MH Benchmark Sub-tasks (I–VI)
- **Y-axis**: Accuracy (0.0–1.0 in 0.2 increments)
- **Legend**:
- Yellow star: Pre. (pre-training)
- Gray circle: Re. (retrieval)
- Blue: GPT-4o
- Orange: Claude 3.7
- Green: Gemini 1.5
- **Legend Position**: Top-right corner
### Detailed Analysis
1. **Sub-task I**:
- GPT-4o: ~0.90
- Claude 3.7: ~0.95
- Gemini 1.5: ~0.62
- Pre.: ~0.88 (yellow star)
- Re.: ~0.85 (gray circle)
2. **Sub-task II**:
- GPT-4o: ~0.38
- Claude 3.7: ~0.36
- Gemini 1.5: ~0.34
- Pre.: ~0.42
- Re.: ~0.60
3. **Sub-task III**:
- GPT-4o: ~0.28
- Claude 3.7: ~0.18
- Gemini 1.5: ~0.24
- Pre.: ~0.20
- Re.: ~0.25
4. **Sub-task IV**:
- GPT-4o: ~0.65
- Claude 3.7: ~0.30
- Gemini 1.5: ~0.40
- Pre.: ~0.35
- Re.: ~0.50
5. **Sub-task V**:
- GPT-4o: ~0.70
- Claude 3.7: ~0.40
- Gemini 1.5: ~0.40
- Pre.: ~0.35
- Re.: ~0.45
6. **Sub-task VI**:
- GPT-4o: ~0.53
- Claude 3.7: ~0.61
- Gemini 1.5: ~0.68
- Pre.: ~0.05
- Re.: ~0.02
### Key Observations
- **Model Performance**:
- GPT-4o dominates in Sub-task I (~0.90) but declines in II–III (~0.28–0.38) before recovering in IV–V (~0.65–0.70).
- Claude 3.7 peaks in Sub-task I (~0.95) and shows gradual improvement in VI (~0.61).
- Gemini 1.5 performs consistently mid-range (0.24–0.68), with its highest accuracy in VI.
- **Pre. vs. Re.**:
- Pre. (yellow stars) generally outperforms Re. (gray circles) except in Sub-task III (~0.20 vs. 0.25).
- Pre. accuracy drops sharply in VI (~0.05), while Re. hits a near-zero floor (~0.02).
### Interpretation
The data suggests:
1. **Task-Specific Strengths**: GPT-4o excels in early sub-tasks (I, V), while Claude 3.7 and Gemini 1.5 improve performance in later sub-tasks (VI).
2. **Pre-training vs. Retrieval**: Pre-training (Pre.) consistently outperforms retrieval (Re.) across most sub-tasks, though the gap narrows in III. The drastic drop in Pre. accuracy in VI implies retrieval may be more critical for complex tasks.
3. **Model Limitations**: All models struggle with Sub-task III, indicating a potential weakness in handling intermediate complexity tasks.
### Spatial Grounding & Trend Verification
- **Legend Alignment**: Colors match legend labels exactly (e.g., blue bars = GPT-4o).
- **Trend Consistency**: GPT-4o’s U-shaped curve (high I, low III, high V) aligns with its accuracy values. Claude 3.7’s gradual rise in VI matches its increasing bar heights.