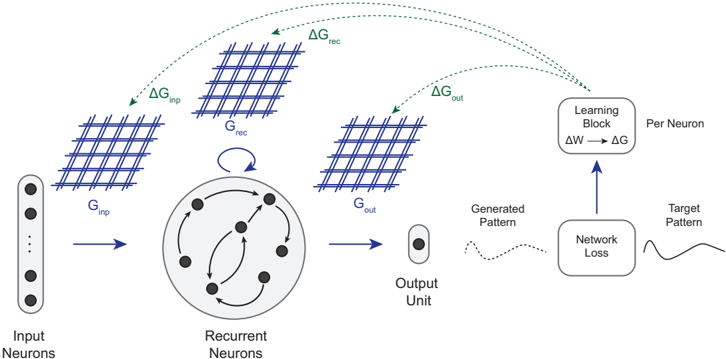
## Diagram: Recurrent Neural Network Architecture with Gradient Flow
### Overview
The diagram illustrates a recurrent neural network (RNN) architecture with explicit gradient flow and learning mechanisms. It shows the interaction between input neurons, recurrent neurons, output units, and a learning block, with gradients (ΔG) propagating through the system to optimize network performance.
### Components/Axes
1. **Input Neurons**: Vertical column on the left, labeled "Input Neurons" with three black dots representing neuron activations.
2. **Recurrent Neurons**: Central circular structure with interconnected black dots and arrows, labeled "Recurrent Neurons."
3. **Output Unit**: Single neuron on the right, labeled "Output Unit."
4. **Learning Block**: Rectangular box labeled "Learning Block" with ΔW → ΔG arrow, connected to "Per Neuron" adjustments.
5. **Network Loss**: Box labeled "Network Loss" with a dashed line to "Generated Pattern" and solid line to "Target Pattern."
6. **Gradients**:
- ΔG_inp (green arrow from Input Neurons to Recurrent Neurons)
- ΔG_rec (green arrow from Recurrent Neurons to Learning Block)
- ΔG_out (green arrow from Output Unit to Learning Block)
### Detailed Analysis
- **Input Flow**: Input neurons (G_inp) feed into recurrent neurons (G_rec), which loop back to themselves via bidirectional arrows.
- **Output Generation**: Recurrent neurons (G_out) produce an output pattern compared to the target pattern.
- **Gradient Propagation**:
- ΔG_inp adjusts input neuron weights.
- ΔG_rec and ΔG_out propagate through the learning block to update weights (ΔW) per neuron.
- **Loss Calculation**: Network loss is computed by comparing generated and target patterns, driving weight adjustments.
### Key Observations
1. **Recurrent Feedback Loop**: The circular arrows in recurrent neurons indicate temporal dependencies and memory retention.
2. **Gradient Hierarchy**: Gradients flow from output (ΔG_out) and hidden layers (ΔG_rec) to input (ΔG_inp), suggesting backpropagation through time.
3. **Learning Mechanism**: The learning block explicitly links weight updates (ΔW) to gradient calculations (ΔG), emphasizing optimization.
### Interpretation
This architecture demonstrates a standard RNN with backpropagation, where:
- **Recurrent connections** enable handling of sequential data by maintaining state.
- **Gradient flow** ensures error correction propagates through all layers, optimizing weights to minimize network loss.
- The **target pattern** serves as a reference for supervised learning, guiding the network to align generated outputs with desired results.
The diagram highlights the interplay between forward propagation (input → output) and backward error correction (gradients → weight updates), critical for training RNNs in tasks like sequence prediction or time-series analysis.