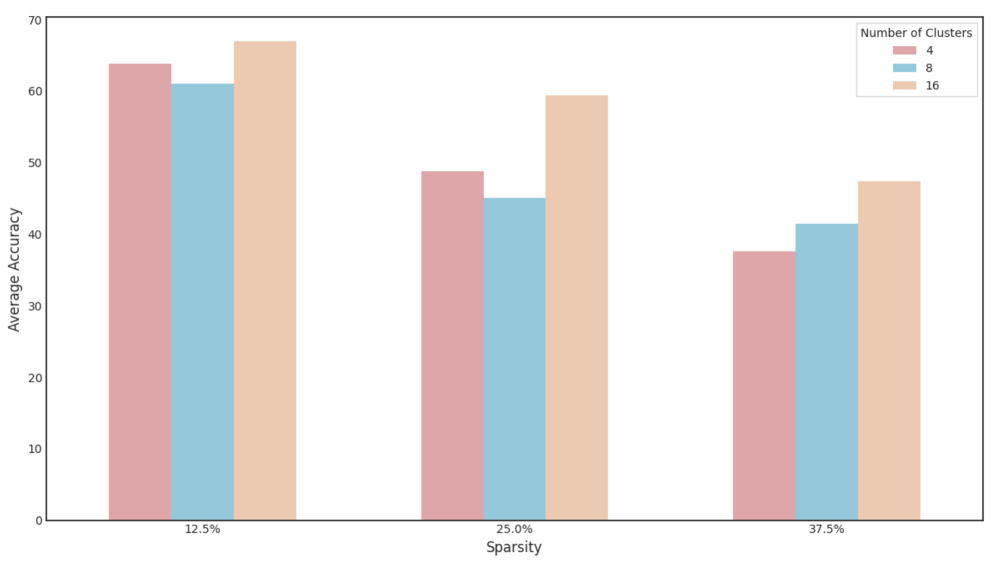
## Bar Chart: Average Accuracy vs. Sparsity for Different Number of Clusters
### Overview
The image is a bar chart comparing the average accuracy of a model at different sparsity levels (12.5%, 25.0%, and 37.5%) for varying numbers of clusters (4, 8, and 16). The chart displays three bars for each sparsity level, each representing a different number of clusters.
### Components/Axes
* **X-axis:** Sparsity, with values 12.5%, 25.0%, and 37.5%.
* **Y-axis:** Average Accuracy, ranging from 0 to 70.
* **Legend (Top-Right):**
* Pink: 4 Clusters
* Light Blue: 8 Clusters
* Peach: 16 Clusters
### Detailed Analysis
The chart presents the average accuracy for different combinations of sparsity and number of clusters.
* **Sparsity 12.5%:**
* 4 Clusters (Pink): Accuracy ~ 63
* 8 Clusters (Light Blue): Accuracy ~ 61
* 16 Clusters (Peach): Accuracy ~ 66
* **Sparsity 25.0%:**
* 4 Clusters (Pink): Accuracy ~ 49
* 8 Clusters (Light Blue): Accuracy ~ 45
* 16 Clusters (Peach): Accuracy ~ 59
* **Sparsity 37.5%:**
* 4 Clusters (Pink): Accuracy ~ 37
* 8 Clusters (Light Blue): Accuracy ~ 41
* 16 Clusters (Peach): Accuracy ~ 47
### Key Observations
* For all cluster sizes, the average accuracy decreases as sparsity increases.
* At each sparsity level, 16 clusters generally yield the highest average accuracy, followed by 4 clusters, and then 8 clusters.
* The difference in average accuracy between different numbers of clusters is more pronounced at lower sparsity levels (12.5% and 25.0%) compared to 37.5%.
### Interpretation
The data suggests that increasing sparsity negatively impacts the average accuracy of the model, regardless of the number of clusters. Using 16 clusters generally results in higher accuracy compared to 4 or 8 clusters, especially when sparsity is lower. The relationship between sparsity and accuracy is likely due to the removal of data points, which reduces the information available for the model to learn from. The varying performance of different cluster sizes may be related to how well the data structure aligns with the clustering algorithm at different sparsity levels.