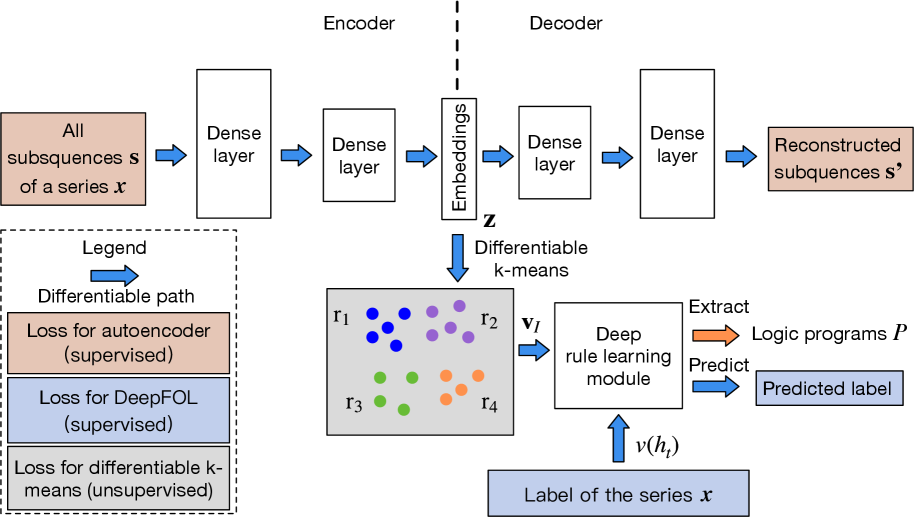
\n
## Diagram: Deep Rule Learning Architecture
### Overview
The image presents a diagram of a deep rule learning architecture. It illustrates the flow of data through an encoder-decoder structure, followed by differentiable k-means clustering and a deep rule learning module for prediction. The diagram includes labeled components, data flow arrows, and a legend explaining the different types of connections and losses.
### Components/Axes
* **Title:** None explicitly given, but the diagram depicts a deep rule learning architecture.
* **Sections:** The diagram is divided into two main sections: Encoder (left) and Decoder (right).
* **Components:**
* "All subsequences s of a series x" (brown box, top-left)
* "Dense layer" (white boxes, top, repeated twice in both Encoder and Decoder)
* "Embeddings z" (vertical gray box, center)
* "Reconstructed subsequences s'" (brown box, top-right)
* "Differentiable k-means" (below Embeddings)
* "r1, r2, r3, r4" (labels for clusters in the k-means output)
* "Deep rule learning module" (white box, right-center)
* "Label of the series x" (light blue box, bottom)
* "Logic programs P" (output of the deep rule learning module)
* "Predicted label" (output of the deep rule learning module)
* **Legend:** (bottom-left)
* Blue arrow: "Differentiable path"
* Light brown box: "Loss for autoencoder (supervised)"
* Light blue box: "Loss for DeepFOL (supervised)"
* Gray box: "Loss for differentiable k-means (unsupervised)"
* **Arrows:** Blue arrows indicate the flow of data/computation. An orange arrow indicates "Extract" and a blue arrow indicates "Predict".
### Detailed Analysis or ### Content Details
1. **Encoder:**
* Starts with "All subsequences s of a series x".
* Passes through two "Dense layer" blocks.
* Outputs "Embeddings z".
2. **Decoder:**
* Receives "Embeddings z".
* Passes through two "Dense layer" blocks.
* Outputs "Reconstructed subsequences s'".
3. **Differentiable k-means:**
* Receives "Embeddings z".
* Clusters the data into four regions labeled "r1", "r2", "r3", and "r4".
* Each region contains data points of a specific color: r1 (blue), r2 (purple), r3 (green), r4 (orange).
* Outputs "vI" to the "Deep rule learning module".
4. **Deep rule learning module:**
* Receives "vI" from the k-means clustering and "v(h)" from the "Label of the series x".
* Extracts "Logic programs P" (orange arrow).
* Predicts "Predicted label" (blue arrow).
### Key Observations
* The architecture combines an autoencoder (encoder-decoder) with k-means clustering and a deep rule learning module.
* The encoder and decoder both use two dense layers.
* The k-means clustering step divides the data into four clusters.
* The deep rule learning module takes input from both the k-means clustering and the label of the series.
### Interpretation
The diagram illustrates a deep learning architecture designed for learning logical rules from sequential data. The encoder-decoder structure likely aims to extract meaningful features from the input series. The k-means clustering step then groups similar subsequences together, and the deep rule learning module learns logical rules based on these clusters and the series labels. This architecture could be used for tasks such as time series classification or anomaly detection, where understanding the underlying logical rules is important. The use of differentiable k-means allows for end-to-end training of the entire architecture.