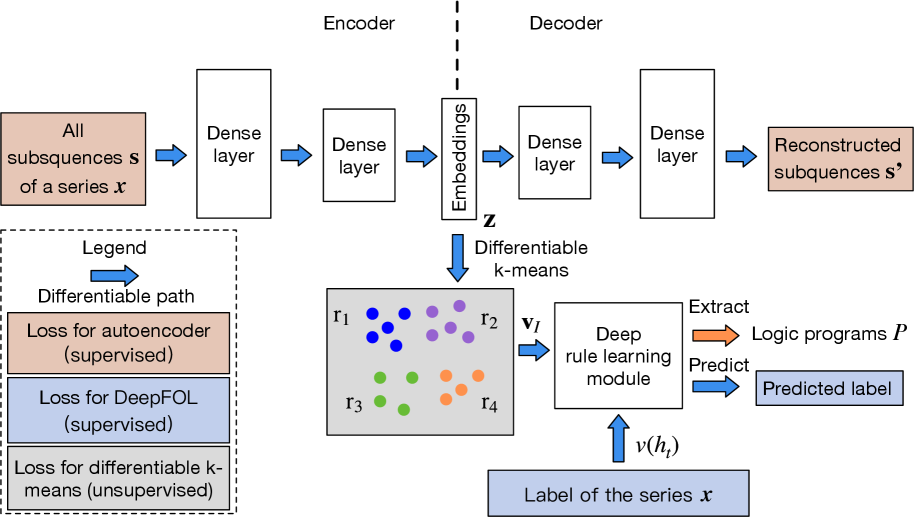
## Diagram: Neural Architecture with Differentiable Clustering and Rule Learning
### Overview
The diagram illustrates a hybrid neural network architecture combining autoencoding, differentiable clustering, and rule-based prediction. It features an encoder-decoder structure for sequence reconstruction, a differentiable k-means module for unsupervised clustering, and a deep rule learning module for supervised prediction. The architecture integrates multiple loss functions and data flows.
### Components/Axes
1. **Encoder-Decoder Path**:
- **Encoder**:
- Input: "All subsequences **s** of a series **x**"
- Two dense layers → Embeddings **z**
- **Decoder**:
- Embeddings **z** → Two dense layers → "Reconstructed subsequences **s'**"
2. **Differentiable k-means Module**:
- Input: Embeddings **z**
- Output: Cluster assignments **r₁, r₂, r₃, r₄** (colored dots: blue, purple, green, orange)
- Legend:
- Blue: **r₁**
- Purple: **r₂**
- Green: **r₃**
- Orange: **r₄**
3. **Deep Rule Learning Module**:
- Input: Cluster assignments **vᵢ** (from **r₁-r₄**)
- Output: "Predicted label" via logic programs **P**
4. **Loss Functions**:
- **Autoencoder loss** (supervised, orange)
- **DeepFOL loss** (supervised, blue)
- **Differentiable k-means loss** (unsupervised, gray)
5. **Data Flow**:
- Input series **x** → Encoder → Embeddings **z** → Decoder (reconstruction) + Differentiable k-means → Deep rule learning → Predicted label **v(hₜ)**
### Detailed Analysis
- **Encoder/Decoder**: Standard dense layer architecture for sequence-to-sequence modeling.
- **Differentiable k-means**: Embeddings are clustered into 4 groups (**r₁-r₄**) with color-coded assignments. The "differentiable" aspect implies gradient-based optimization of cluster assignments during training.
- **Deep Rule Learning**: Takes cluster assignments as input to predict labels, suggesting rule-based reasoning over learned features.
- **Loss Functions**:
- Supervised losses (autoencoder, DeepFOL) optimize reconstruction and rule adherence.
- Unsupervised loss (differentiable k-means) optimizes cluster quality.
### Key Observations
1. **Hybrid Learning**: Combines supervised (autoencoder, DeepFOL) and unsupervised (k-means) training objectives.
2. **Cluster-Aware Prediction**: The deep rule learning module uses cluster assignments (**vᵢ**) to make predictions, implying rules are applied per-cluster.
3. **Differentiable Clustering**: Unlike traditional k-means, cluster assignments are learned end-to-end via gradients.
4. **Label Prediction**: Final output (**v(hₜ)**) depends on both feature embeddings and cluster membership.
### Interpretation
This architecture demonstrates a novel integration of:
1. **Feature Learning**: Autoencoder compresses input sequences into meaningful embeddings.
2. **Unsupervised Structure Discovery**: Differentiable k-means identifies latent clusters in the data.
3. **Rule-Based Reasoning**: The deep rule learning module applies logical programs to cluster-specific patterns.
The model's strength lies in its ability to:
- Learn compressed representations (**z**)
- Discover natural groupings in data (**r₁-r₄**)
- Apply interpretable rules to clusters for prediction
The use of differentiable clustering is particularly innovative, allowing the model to adapt cluster assignments during training rather than fixing them post-hoc. This could improve performance on dynamic or evolving datasets where cluster structure changes over time.