\n
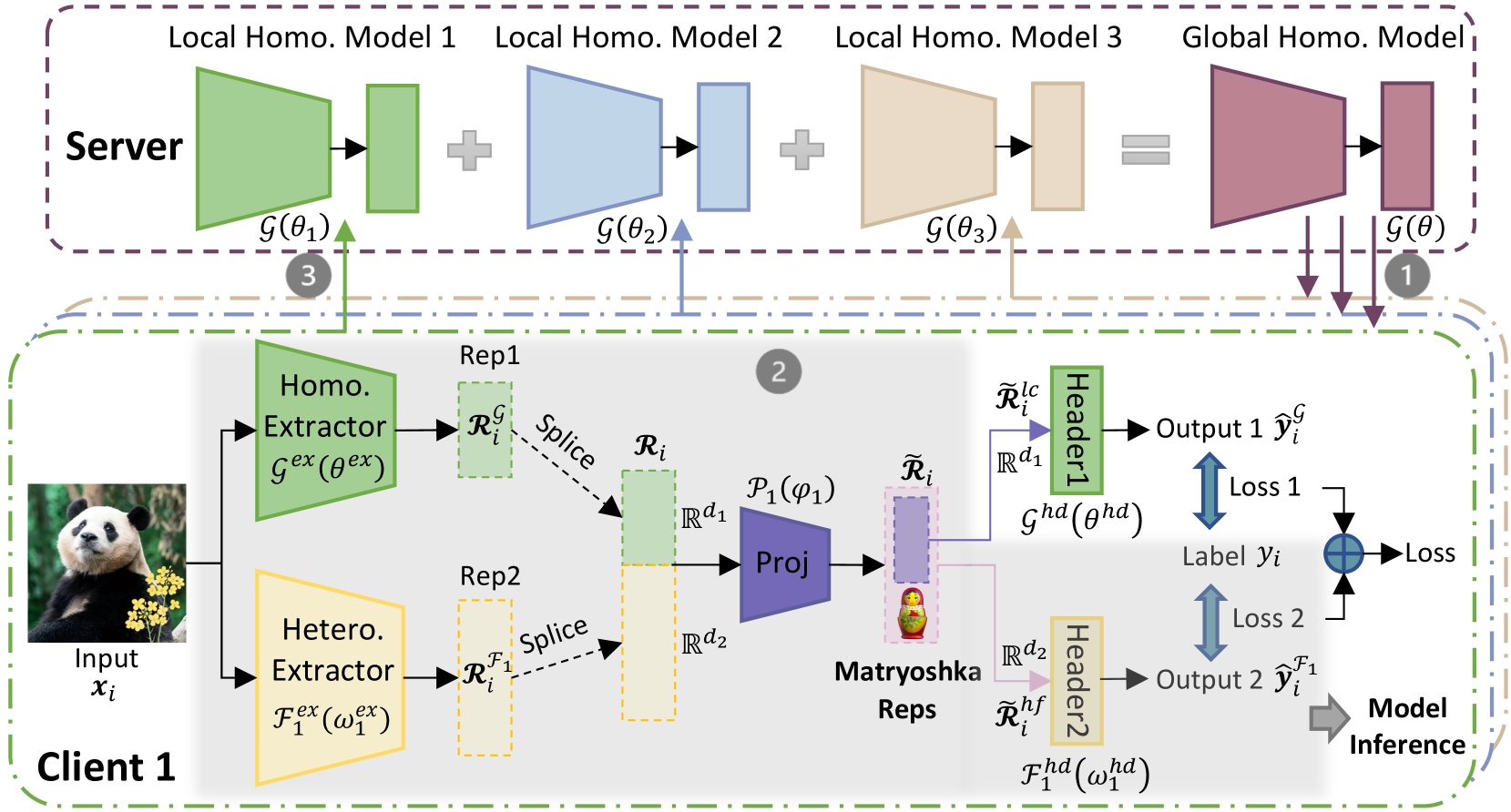
## Diagram: Federated Learning with Matryoshka Representation
### Overview
This diagram illustrates a federated learning system employing a Matryoshka representation for privacy-preserving model training. The system involves a server and multiple clients (Client 1 is shown). Clients train local models on their private data and send model updates to the server, which aggregates them to create a global model. The Matryoshka representation adds an additional layer of privacy by encoding client data into a series of nested representations.
### Components/Axes
The diagram is segmented into two main sections: "Server" (top, light blue) and "Client 1" (bottom, yellow). Key components include:
* **Input (xᵢ):** Image of two pandas.
* **Homo. Extractor (Gex(θex)):** Homogeneous Extractor.
* **Hetero. Extractor (Tex(ωex)):** Heterogeneous Extractor.
* **Rep1 & Rep2:** Representations from the Homo. and Hetero. Extractors respectively.
* **Splice:** Operation combining Rep1 and Rep2.
* **Proj:** Projection operation.
* **Matryoshka Reps:** Nested representations (orange, apple, banana).
* **Header1 & Header2:** Classification headers.
* **Output 1 (ŷᵢ) & Output 2 (ŷᵢ¹):** Model outputs.
* **Loss 1 & Loss 2:** Loss functions.
* **Label (yᵢ):** Ground truth label.
* **Local Homo. Model 1, 2, 3:** Local homogeneous models on the server.
* **Global Homo. Model:** Global homogeneous model on the server.
* **G(θ), G(θ₁), G(θ₂), G(θ₃):** Model functions with parameters.
* **Rᵢ, Rᵢ¹, Rᵢᶜ, Rᵢᵈ¹, Rᵢᵈ²:** Intermediate representations.
* **Ghd(ghd), Fhd(whd):** Header functions.
* **Arrows with numbers (1, 2, 3):** Indicate the flow of information and aggregation steps.
### Detailed Analysis or Content Details
The diagram depicts the following flow:
1. **Client-Side Processing:**
* An input image (xᵢ) of two pandas is fed into both a Homogeneous Extractor (Gex(θex)) and a Heterogeneous Extractor (Tex(ωex)).
* The Homo. Extractor produces representation Rep1 (Rᵢᶜ).
* The Hetero. Extractor produces representation Rep2 (Rᵢᵈ²).
* Rep1 and Rep2 are spliced together to create Rᵢ.
* Rᵢ is then projected (Proj) to create a Matryoshka representation (tilde Rᵢ) containing nested representations (orange, apple, banana).
* The Matryoshka representation is fed into Header1 and Header2.
* Header1 produces Output 1 (ŷᵢ) and calculates Loss 1 based on the Label (yᵢ).
* Header2 produces Output 2 (ŷᵢ¹) and calculates Loss 2.
* Model Inference is performed.
2. **Server-Side Aggregation:**
* The server hosts three Local Homo. Models (Model 1, Model 2, Model 3) with parameters θ₁, θ₂, and θ₃ respectively.
* Each local model receives updates from clients (indicated by arrow 3).
* The server aggregates the updates to create a Global Homo. Model with parameters θ.
* The Global Homo. Model is then used to generate predictions.
3. **Information Flow:**
* Arrow 1 indicates the flow of the Global Homo. Model to the clients.
* Arrow 2 indicates the flow of the Matryoshka representation from the client to the server.
* Arrow 3 indicates the flow of updates from the client's Homo. Extractor to the server's Local Homo. Models.
### Key Observations
* The system utilizes both homogeneous and heterogeneous extractors to process client data.
* The Matryoshka representation appears to be a key component for privacy preservation, encoding data into nested representations.
* The server aggregates updates from multiple clients to create a global model.
* The diagram highlights the separation between client-side processing and server-side aggregation.
* The use of Loss 1 and Loss 2 suggests a multi-task learning or auxiliary loss setup.
### Interpretation
This diagram demonstrates a federated learning approach designed to protect client privacy. The use of both homogeneous and heterogeneous extractors suggests the system can handle diverse data types or feature spaces. The Matryoshka representation likely adds an additional layer of privacy by obscuring the original data while still allowing the model to learn useful features. The server's role is to aggregate model updates without directly accessing the raw client data. The two headers and associated losses suggest a potential for learning multiple representations or tasks simultaneously. The overall architecture aims to balance model accuracy with data privacy, a crucial consideration in many real-world applications. The nested representations (Matryoshka) are a clever way to encode information in a hierarchical manner, potentially making it more difficult to reconstruct the original data. The diagram suggests a complex system with multiple stages of processing and aggregation, designed to achieve a high level of privacy and accuracy.