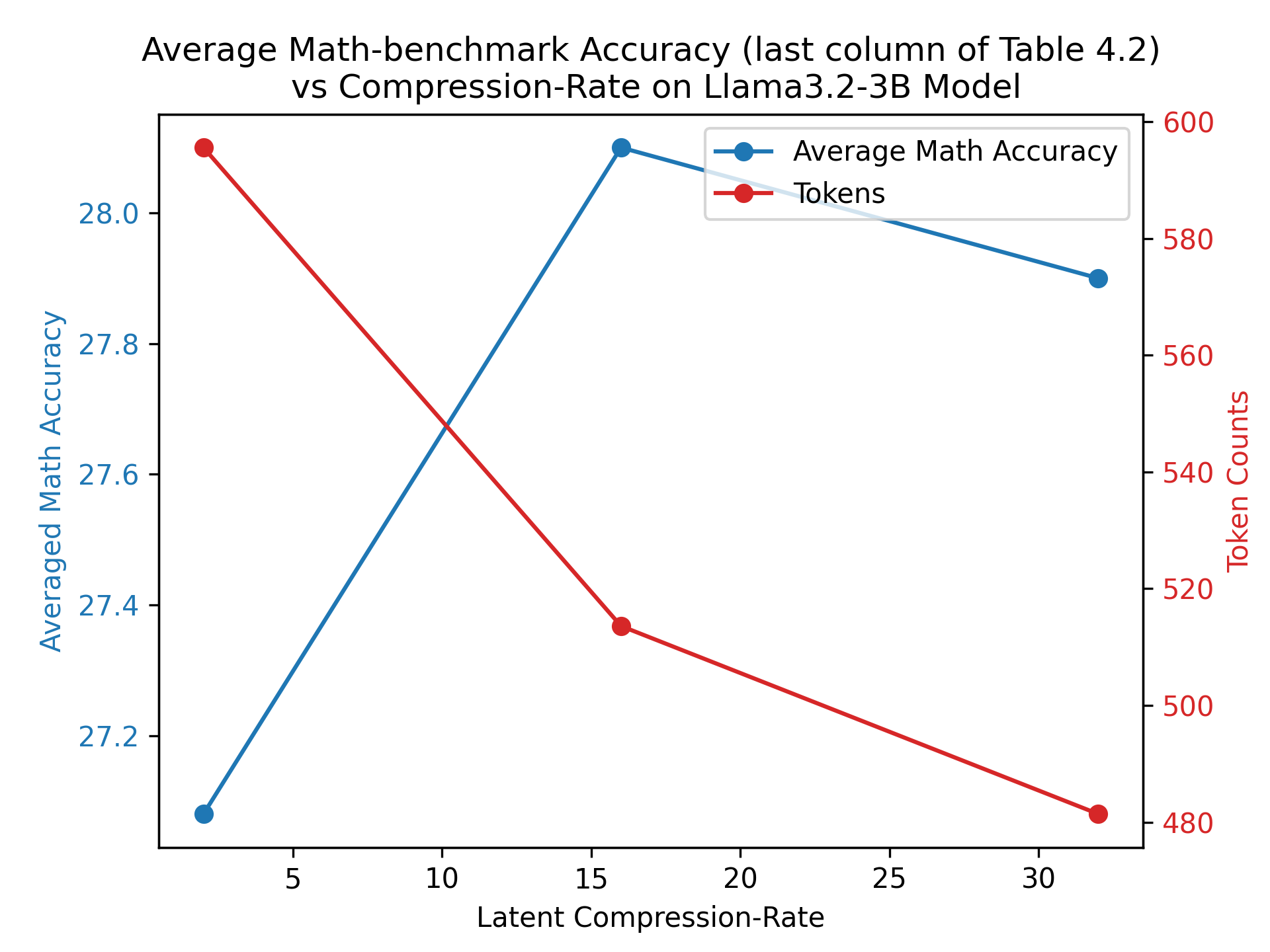
## Line Chart: Average Math-benchmark Accuracy vs Compression-Rate
### Overview
The image is a line chart comparing the average math accuracy and token counts against the latent compression rate on the Llama3.2-3B model. The x-axis represents the latent compression rate, the left y-axis represents the average math accuracy, and the right y-axis represents the token counts. There are two data series plotted: average math accuracy (blue) and tokens (red).
### Components/Axes
* **Title:** Average Math-benchmark Accuracy (last column of Table 4.2) vs Compression-Rate on Llama3.2-3B Model
* **X-axis:**
* Label: Latent Compression-Rate
* Scale: 5, 10, 15, 20, 25, 30
* **Left Y-axis:**
* Label: Averaged Math Accuracy
* Scale: 27.2, 27.4, 27.6, 27.8, 28.0
* **Right Y-axis:**
* Label: Token Counts
* Scale: 480, 500, 520, 540, 560, 580, 600
* **Legend:** Located in the top-right corner.
* Average Math Accuracy (blue line)
* Tokens (red line)
### Detailed Analysis
* **Average Math Accuracy (blue line):**
* Trend: Initially increases sharply, then decreases slightly.
* Data Points:
* At Latent Compression-Rate = 4, Average Math Accuracy ≈ 27.1
* At Latent Compression-Rate = 16, Average Math Accuracy ≈ 28.0
* At Latent Compression-Rate = 32, Average Math Accuracy ≈ 27.9
* **Tokens (red line):**
* Trend: Decreases consistently.
* Data Points:
* At Latent Compression-Rate = 4, Token Counts ≈ 590
* At Latent Compression-Rate = 16, Token Counts ≈ 520
* At Latent Compression-Rate = 32, Token Counts ≈ 480
### Key Observations
* The average math accuracy peaks at a latent compression rate of approximately 16.
* The token count decreases as the latent compression rate increases.
* There appears to be an inverse relationship between token count and latent compression rate.
* The average math accuracy increases sharply between latent compression rates of 4 and 16, then decreases slightly between 16 and 32.
### Interpretation
The chart suggests that increasing the latent compression rate initially improves the average math accuracy, but beyond a certain point (around 16), further increases in the compression rate lead to a slight decrease in accuracy. Simultaneously, increasing the latent compression rate consistently reduces the number of tokens. This indicates a trade-off between model accuracy and the number of tokens required. The optimal compression rate would likely depend on the specific application and the relative importance of accuracy versus token count.