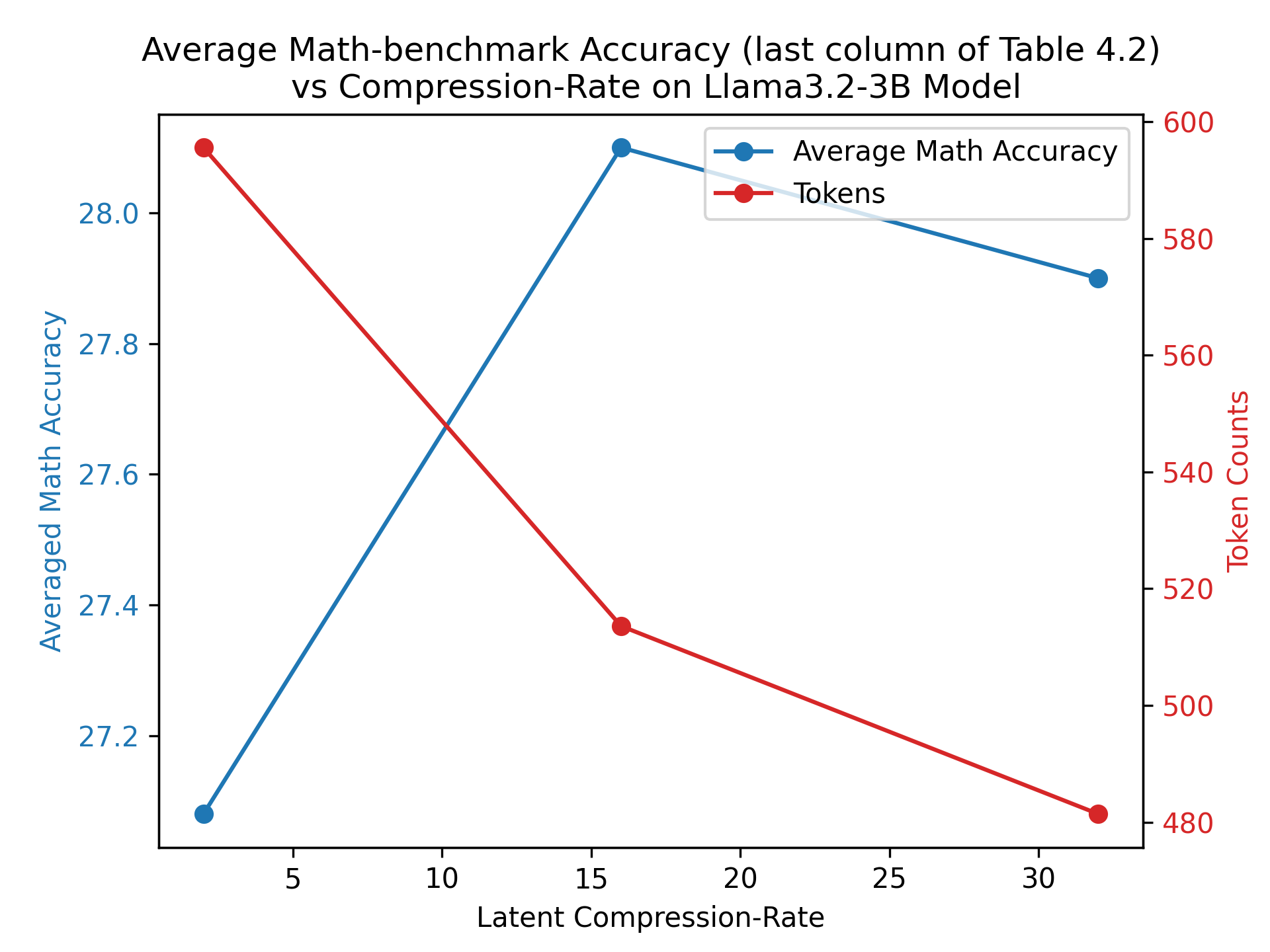
## Line Chart: Average Math-benchmark Accuracy vs Compression-Rate on Llama3.2-3B Model
### Overview
This line chart depicts the relationship between latent compression rate and both average math accuracy and token counts for the Llama3.2-3B model. Two data series are presented: average math accuracy (plotted against the primary y-axis) and token counts (plotted against the secondary y-axis). The data appears to be derived from the last column of Table 4.2.
### Components/Axes
* **Title:** Average Math-benchmark Accuracy (last column of Table 4.2) vs Compression-Rate on Llama3.2-3B Model
* **X-axis:** Latent Compression-Rate (ranging from approximately 0 to 30, with markers at 5, 10, 15, 20, 25, and 30)
* **Primary Y-axis (left):** Averaged Math Accuracy (ranging from approximately 27.2 to 28.1)
* **Secondary Y-axis (right):** Token Counts (ranging from approximately 480 to 600)
* **Legend:**
* Blue Line: Average Math Accuracy
* Red Line: Tokens
### Detailed Analysis
**Average Math Accuracy (Blue Line):**
The blue line representing average math accuracy exhibits an upward trend initially, then plateaus.
* At a compression rate of 0, the accuracy is approximately 27.1.
* At a compression rate of 5, the accuracy increases to approximately 27.3.
* At a compression rate of 10, the accuracy increases to approximately 27.7.
* At a compression rate of 15, the accuracy peaks at approximately 28.1.
* At a compression rate of 20, the accuracy remains at approximately 28.1.
* At a compression rate of 25, the accuracy decreases slightly to approximately 27.9.
* At a compression rate of 30, the accuracy decreases to approximately 27.8.
**Token Counts (Red Line):**
The red line representing token counts shows a consistent downward trend.
* At a compression rate of 0, the token count is approximately 590.
* At a compression rate of 5, the token count decreases to approximately 570.
* At a compression rate of 10, the token count decreases to approximately 540.
* At a compression rate of 15, the token count decreases to approximately 525.
* At a compression rate of 20, the token count decreases to approximately 505.
* At a compression rate of 25, the token count decreases to approximately 495.
* At a compression rate of 30, the token count decreases to approximately 480.
### Key Observations
* There is a positive correlation between compression rate and math accuracy up to a compression rate of 15. Beyond this point, accuracy plateaus and then slightly declines.
* There is a strong negative correlation between compression rate and token counts. As the compression rate increases, the number of tokens decreases.
* The peak math accuracy is achieved at a compression rate of 15.
* The most significant drop in token count occurs between compression rates of 0 and 10.
### Interpretation
The data suggests that increasing the compression rate initially improves math accuracy for the Llama3.2-3B model, but this improvement has diminishing returns. Beyond a certain point (around a compression rate of 15), further compression does not lead to increased accuracy and may even slightly reduce it. The consistent decrease in token counts with increasing compression rate indicates that compression is effectively reducing the model's size and computational requirements.
The relationship between accuracy and compression rate could be due to a trade-off between model complexity and information loss. Higher compression rates may lead to a more compact model, but also to a loss of information that is crucial for accurate math reasoning. The plateau and slight decline in accuracy at higher compression rates suggest that the model is reaching a point where further compression is detrimental to its performance.
The data is explicitly linked to "last column of Table 4.2", suggesting this chart is a visualization of a specific data point within a larger study. Further investigation of Table 4.2 would be necessary to understand the context of this data and the specific compression techniques used.