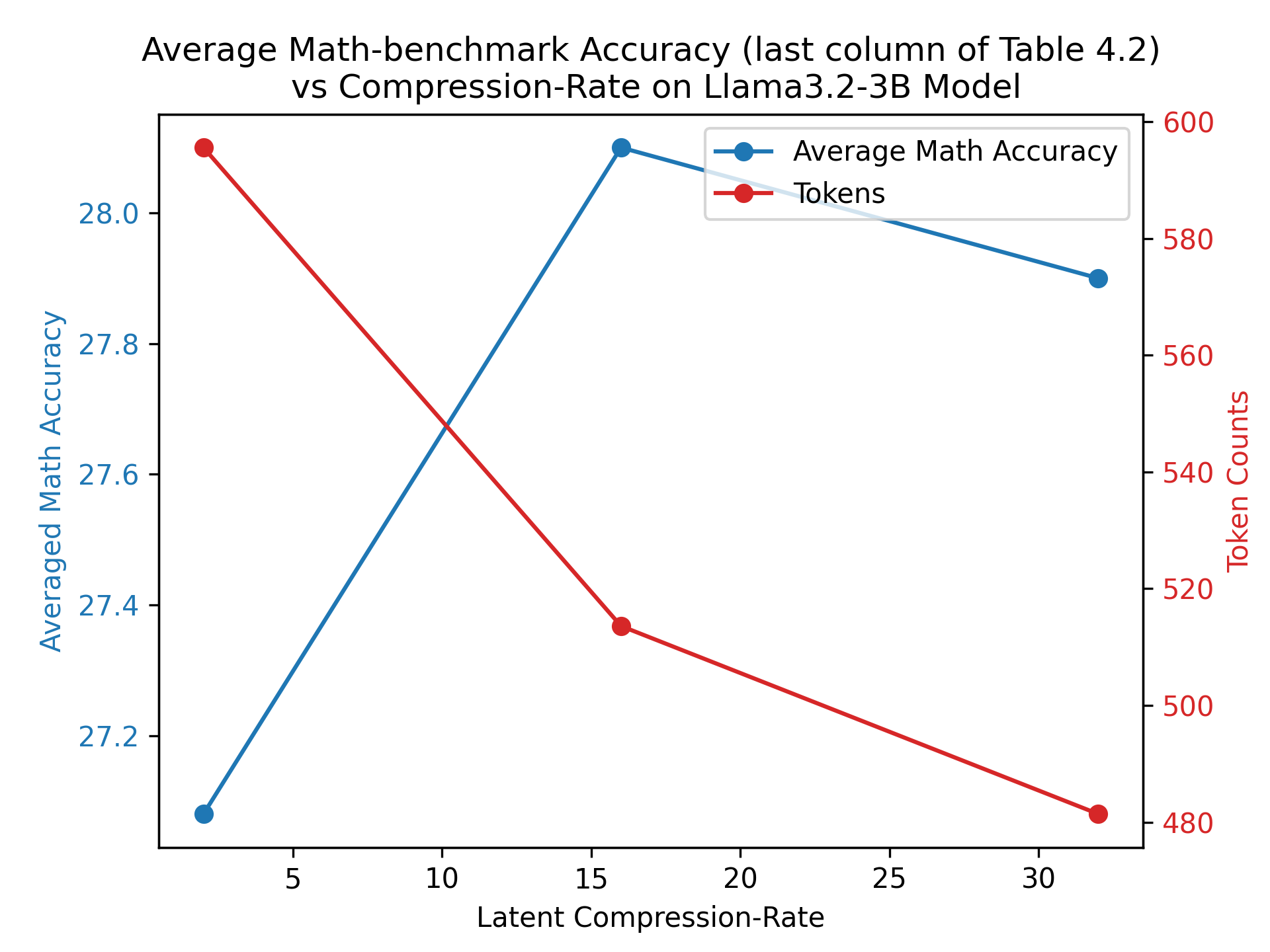
## Line Chart: Average Math-benchmark Accuracy vs Compression-Rate on Llama3.2-3B Model
### Overview
The chart visualizes the relationship between **Latent Compression-Rate** (x-axis) and two metrics: **Averaged Math Accuracy** (y-axis, blue line) and **Token Counts** (y-axis, red line). The data suggests a non-linear trade-off between compression efficiency and model performance.
### Components/Axes
- **X-axis (Latent Compression-Rate)**: Ranges from 5 to 30 in increments of 5.
- **Y-axis (Averaged Math Accuracy)**: Ranges from 27.2 to 28.0 in increments of 0.2.
- **Legend**: Located in the top-right corner, with:
- **Blue line/circles**: Represents **Average Math Accuracy**.
- **Red line/circles**: Represents **Token Counts**.
### Detailed Analysis
#### Average Math Accuracy (Blue Line)
- **Data Points**:
- At **5**: 27.2
- At **15**: 28.1 (peak)
- At **30**: 27.9
- **Trend**: Increases sharply from 5 to 15, then declines slightly from 15 to 30.
#### Token Counts (Red Line)
- **Data Points**:
- At **5**: 580
- At **15**: 520
- At **30**: 480
- **Trend**: Consistently decreases as compression-rate increases.
### Key Observations
1. **Optimal Compression-Rate for Accuracy**: The highest math accuracy (28.1) occurs at a compression-rate of 15, suggesting a potential "sweet spot" before performance degradation.
2. **Token Efficiency**: Token counts drop linearly (580 → 480) as compression-rate increases, indicating reduced computational/resource demands.
3. **Divergence at Extremes**: At compression-rate 5, accuracy is lowest (27.2) but tokens are highest (580). At 30, accuracy stabilizes near 27.9 while tokens drop to 480.
### Interpretation
The chart highlights a **non-linear trade-off**:
- **Math Accuracy** improves with moderate compression (up to 15) but declines at higher rates (30), possibly due to over-compression degrading model fidelity.
- **Token Counts** decrease monotonically, reflecting efficient resource utilization at higher compression rates.
- The divergence between the two metrics implies a **compromise**: Higher compression reduces tokens but risks accuracy loss beyond a critical threshold.
This analysis aligns with typical model compression behavior, where excessive compression can harm performance despite resource savings.