\n
## Bar Charts: Accuracy of Prediction Models
### Overview
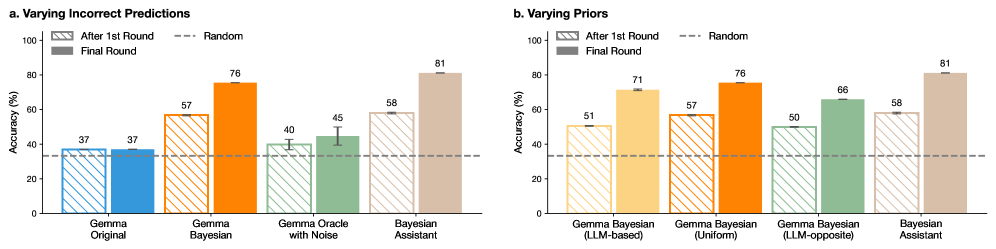
The image presents two bar charts (labeled 'a' and 'b') comparing the accuracy of different prediction models under varying conditions. Chart 'a' focuses on "Varying Incorrect Predictions," while chart 'b' focuses on "Varying Priors." Both charts measure accuracy as a percentage, ranging from 0% to 100%, on the y-axis. The x-axis represents different models or configurations. Each model is evaluated after the first round and after a final round of processing. A "Random" accuracy baseline is also provided.
### Components/Axes
**Common Elements:**
* **Y-axis:** Accuracy (%) - Scale ranges from 0 to 100, with increments of 20.
* **Legend:**
* "After 1st Round" (Blue)
* "Final Round" (Orange)
* "Random" (Gray dashed line)
* **X-axis:** Model/Configuration names.
**Chart a (Varying Incorrect Predictions):**
* **X-axis Labels:** Gemma Original, Gemma Bayesian, Gemma Oracle with Noise, Bayesian Assistant.
**Chart b (Varying Priors):**
* **X-axis Labels:** Gemma Bayesian (LLM-based), Gemma Bayesian (Uniform), Gemma Bayesian (LLM-opposite), Bayesian Assistant.
### Detailed Analysis or Content Details
**Chart a (Varying Incorrect Predictions):**
* **Gemma Original:** After 1st Round: Approximately 37%. Final Round: Approximately 37%.
* **Gemma Bayesian:** After 1st Round: Approximately 57%. Final Round: Approximately 76%.
* **Gemma Oracle with Noise:** After 1st Round: Approximately 40% with an error bar extending roughly +/- 5%. Final Round: Approximately 45% with an error bar extending roughly +/- 5%.
* **Bayesian Assistant:** After 1st Round: Approximately 58%. Final Round: Approximately 81%.
* **Random:** Approximately 37% (represented by a dashed gray line).
**Chart b (Varying Priors):**
* **Gemma Bayesian (LLM-based):** After 1st Round: Approximately 51%. Final Round: Approximately 71%.
* **Gemma Bayesian (Uniform):** After 1st Round: Approximately 57%. Final Round: Approximately 76%.
* **Gemma Bayesian (LLM-opposite):** After 1st Round: Approximately 50%. Final Round: Approximately 66%.
* **Bayesian Assistant:** After 1st Round: Approximately 58%. Final Round: Approximately 81%.
* **Random:** Approximately 37% (represented by a dashed gray line).
### Key Observations
* In both charts, the "Bayesian Assistant" consistently achieves the highest accuracy in the final round, reaching approximately 81%.
* The "Random" baseline accuracy is around 37% in both charts.
* In Chart a, the "Gemma Original" model shows no improvement between the first and final rounds.
* In Chart a, the "Gemma Bayesian" model shows a significant improvement from the first to the final round.
* In Chart b, all models show improvement from the first to the final round.
* The error bars on "Gemma Oracle with Noise" in Chart a indicate a higher degree of uncertainty in its performance.
### Interpretation
The data suggests that incorporating Bayesian methods, particularly when used with an assistant model, significantly improves prediction accuracy. The "Bayesian Assistant" consistently outperforms other models across both experimental setups.
The difference between Chart a and Chart b highlights the impact of the type of incorrect predictions and priors used. Chart a, focusing on varying incorrect predictions, shows that the "Gemma Original" model is unable to learn from its mistakes, while the "Gemma Bayesian" model benefits from the Bayesian approach. Chart b, focusing on varying priors, demonstrates that the choice of prior (LLM-based, Uniform, LLM-opposite) influences performance, but the Bayesian Assistant remains the most robust.
The consistent performance of the "Random" baseline suggests a lower bound on achievable accuracy. The error bars on the "Gemma Oracle with Noise" model indicate that adding noise can introduce uncertainty, potentially hindering performance. The overall trend indicates that Bayesian approaches are effective in improving prediction accuracy, especially when combined with an assistant model capable of leveraging prior knowledge and learning from errors.