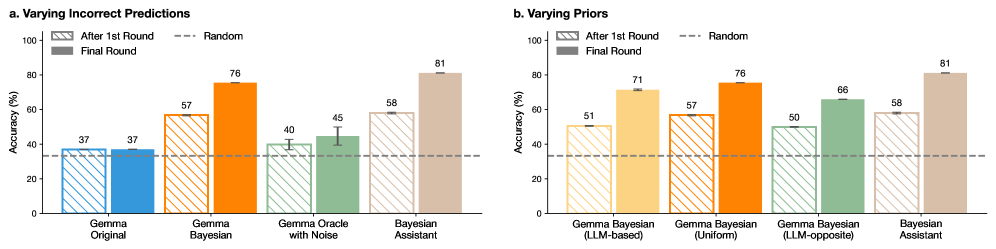
## Bar Chart: Model Accuracy Comparison Across Scenarios
### Overview
The image presents two grouped bar charts comparing model accuracy across different configurations and scenarios. The charts are divided into two sections:
- **a. Varying Incorrect Predictions**
- **b. Varying Priors**
Each section evaluates four models (Gemma Original, Gemma Bayesian, Gemma Oracle with Noise, Bayesian Assistant in part a; Gemma Bayesian variants and Bayesian Assistant in part b) across three evaluation stages: After 1st Round, Random baseline, and Final Round. Accuracy is measured in percentage.
---
### Components/Axes
#### **Part a: Varying Incorrect Predictions**
- **X-axis (Categories)**:
- Gemma Original
- Gemma Bayesian
- Gemma Oracle with Noise
- Bayesian Assistant
- **Y-axis (Scale)**: Accuracy (%) from 0 to 100.
- **Legend**:
- **After 1st Round**: Striped bars (light gray with diagonal lines).
- **Random**: Dashed horizontal line at 37%.
- **Final Round**: Solid bars (dark gray).
#### **Part b: Varying Priors**
- **X-axis (Categories)**:
- Gemma Bayesian (LLM-based)
- Gemma Bayesian (Uniform)
- Gemma Bayesian (LLM-opposite)
- Bayesian Assistant
- **Y-axis (Scale)**: Accuracy (%) from 0 to 100.
- **Legend**: Same as part a (striped, dashed, solid).
---
### Detailed Analysis
#### **Part a: Varying Incorrect Predictions**
- **Gemma Original**:
- After 1st Round: 37% (striped, matches Random baseline).
- Final Round: 37% (solid, no improvement).
- **Gemma Bayesian**:
- After 1st Round: 57% (striped).
- Final Round: 76% (solid, +19% improvement).
- **Gemma Oracle with Noise**:
- After 1st Round: 40% (striped).
- Final Round: 45% (solid, +5% improvement).
- **Bayesian Assistant**:
- After 1st Round: 58% (striped).
- Final Round: 81% (solid, +23% improvement).
#### **Part b: Varying Priors**
- **Gemma Bayesian (LLM-based)**:
- After 1st Round: 51% (striped).
- Final Round: 71% (solid, +20% improvement).
- **Gemma Bayesian (Uniform)**:
- After 1st Round: 57% (striped).
- Final Round: 76% (solid, +19% improvement).
- **Gemma Bayesian (LLM-opposite)**:
- After 1st Round: 50% (striped).
- Final Round: 66% (solid, +16% improvement).
- **Bayesian Assistant**:
- After 1st Round: 58% (striped).
- Final Round: 81% (solid, +23% improvement).
---
### Key Observations
1. **Bayesian Assistant Dominance**:
- Achieves the highest Final Round accuracy (81%) in both scenarios, outperforming all other models by a significant margin.
2. **Model Improvement Trends**:
- All models except **Gemma Original** show improvement from the first to the final round.
- **Gemma Bayesian (LLM-based)** and **Gemma Bayesian (Uniform)** demonstrate the largest gains (+20% and +19%, respectively).
3. **Noise Sensitivity**:
- **Gemma Oracle with Noise** (part a) has the lowest Final Round accuracy (45%), highlighting vulnerability to input quality.
4. **Random Baseline**:
- The dashed line at 37% serves as a reference, showing that even the weakest models (e.g., Gemma Original) slightly outperform random guessing.
---
### Interpretation
- **Bayesian Assistant's Superiority**:
The consistent top performance of the Bayesian Assistant suggests it is robust to both incorrect predictions and prior variations, making it the most reliable model in these scenarios.
- **Gemma Bayesian Variants**:
The LLM-based and Uniform configurations outperform the LLM-opposite variant, indicating that alignment with the model's training framework (LLM) enhances accuracy.
- **Noise Impact**:
The Gemma Oracle with Noise model’s poor performance underscores the importance of clean, high-quality data for accurate predictions.
- **Iterative Refinement**:
The improvement from the first to the final round across most models implies that iterative adjustments or additional training phases enhance performance.
This analysis highlights the critical role of model architecture (e.g., Bayesian methods) and data quality in achieving high accuracy, with the Bayesian Assistant emerging as the optimal choice for these tasks.