## Diagram: Training and Inference Phases for Knowledge Graph Reasoning
### Overview
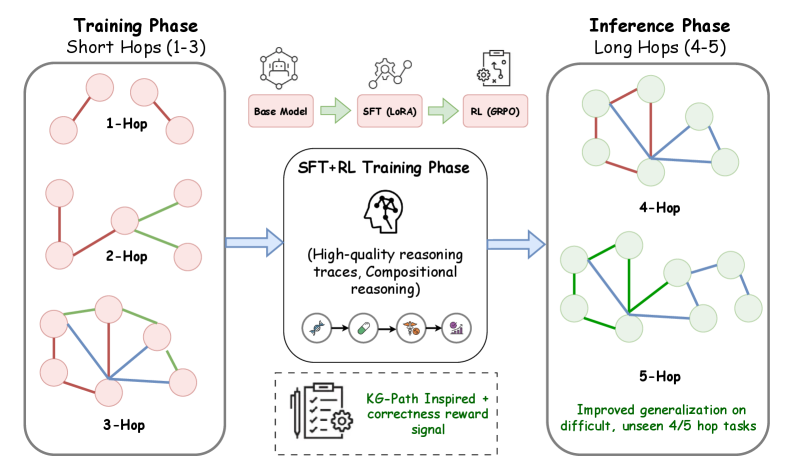
The image illustrates a diagram depicting the training and inference phases for a knowledge graph reasoning model. The diagram shows how the model is trained using short hops (1-3) and then applied to inference with long hops (4-5). The training phase involves a base model, SFT (LoRA), and RL (GRPO), leading to high-quality reasoning traces and compositional reasoning. The inference phase demonstrates improved generalization on difficult, unseen 4/5 hop tasks.
### Components/Axes
* **Title:** Training and Inference Phases for Knowledge Graph Reasoning
* **Left Region:** Training Phase, Short Hops (1-3)
* **1-Hop:** A graph with two nodes connected by a red line.
* **2-Hop:** A graph with four nodes connected by red and green lines.
* **3-Hop:** A graph with seven nodes connected by red, green, and blue lines.
* **Middle Section:**
* **Base Model:** An icon representing a base model.
* **SFT (LoRA):** An icon representing SFT (LoRA).
* **RL (GRPO):** An icon representing RL (GRPO).
* **SFT+RL Training Phase:** A central box containing a brain icon and the text "(High-quality reasoning traces, Compositional reasoning)".
* Icons representing DNA, a pill, a transfer, and a bar graph.
* **KG-Path Inspired + correctness reward signal:** A clipboard icon with a gear and checkmarks.
* **Right Region:** Inference Phase, Long Hops (4-5)
* **4-Hop:** A graph with several nodes connected by red and blue lines.
* **5-Hop:** A graph with several nodes connected by green and blue lines.
* **Improved generalization on difficult, unseen 4/5 hop tasks:** Text describing the outcome of the inference phase.
### Detailed Analysis
* **Training Phase (Short Hops 1-3):**
* **1-Hop:** Two nodes connected by a single red edge.
* **2-Hop:** Four nodes with red and green edges connecting them.
* **3-Hop:** Seven nodes with red, green, and blue edges connecting them.
* **SFT+RL Training Phase:**
* The process starts with a "Base Model" and progresses through "SFT (LoRA)" and "RL (GRPO)".
* The central box represents the "SFT+RL Training Phase", which results in "(High-quality reasoning traces, Compositional reasoning)".
* The "KG-Path Inspired + correctness reward signal" provides feedback during training.
* **Inference Phase (Long Hops 4-5):**
* **4-Hop:** A graph with nodes connected by red and blue edges.
* **5-Hop:** A graph with nodes connected by green and blue edges.
* The inference phase results in "Improved generalization on difficult, unseen 4/5 hop tasks".
### Key Observations
* The diagram illustrates a progression from simple graphs (1-Hop) to more complex graphs (5-Hop).
* The training phase involves a combination of SFT and RL techniques.
* The inference phase demonstrates the model's ability to generalize to unseen tasks.
* The color of the edges in the graphs changes from red to green and blue as the number of hops increases.
### Interpretation
The diagram illustrates a knowledge graph reasoning model's training and inference process. The model is trained on short hops (1-3) using a combination of supervised fine-tuning (SFT) and reinforcement learning (RL). This training process results in high-quality reasoning traces and compositional reasoning abilities. The trained model is then applied to inference on long hops (4-5), demonstrating improved generalization on difficult, unseen tasks. The diagram highlights the importance of training with a combination of techniques to achieve good generalization performance. The KG-Path inspired reward signal likely guides the model towards more relevant and accurate reasoning paths within the knowledge graph.