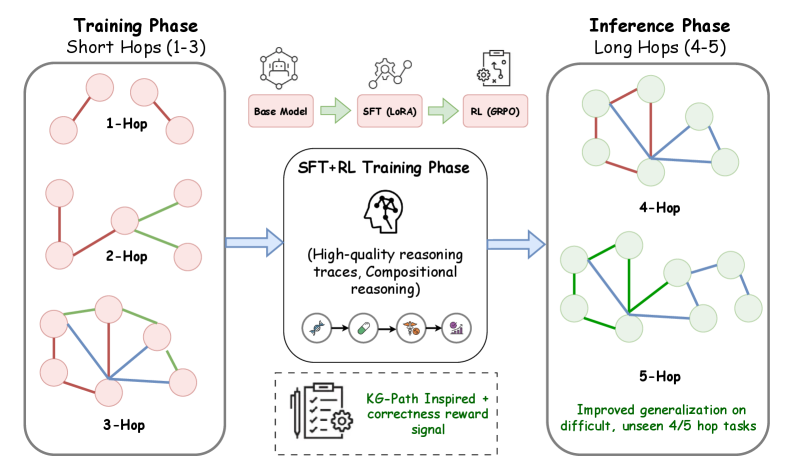
## Flowchart: Multi-Hop Reasoning Model Training and Inference Pipeline
### Overview
The diagram illustrates a two-phase pipeline for training and deploying a multi-hop reasoning model. The left side shows the **Training Phase** focused on short-hop reasoning (1-3 hops), while the right side demonstrates the **Inference Phase** handling long-hop reasoning (4-5 hops). A central **SFT+RL Training Phase** bridges the two, emphasizing high-quality reasoning traces and compositional reasoning.
---
### Components/Axes
1. **Training Phase (Left)**
- **Short Hops (1-3)**
- 1-Hop: Simple direct connections (pink nodes)
- 2-Hop: Two-step connections (pink nodes with green/blue edges)
- 3-Hop: Complex three-step connections (pink nodes with green/blue edges)
- **Flow Progression**
- Base Model → SFT (LoRA) → RL (GRPO) → SFT+RL Training Phase
2. **Inference Phase (Right)**
- **Long Hops (4-5)**
- 4-Hop: Four-step connections (light green nodes with blue/green edges)
- 5-Hop: Five-step connections (light green nodes with blue/green edges)
- **Performance Note**: "Improved generalization on difficult, unseen 4/5 hop tasks"
3. **Central SFT+RL Training Phase**
- **Key Features**
- High-quality reasoning traces
- Compositional reasoning
- KG-Path Inspired + correctness reward signal (bottom section with checklist/gear icon)
4. **Visual Elements**
- Arrows indicate flow direction (blue)
- Node colors: Pink (training), Light Green (inference)
- Edge colors: Red (training), Blue/Green (inference)
- Icons: Brain (reasoning), checklist (KG-Path), gear (reward signal)
---
### Detailed Analysis
- **Training Phase Flow**:
- Starts with a **Base Model** (hexagon icon)
- Progresses through **SFT (LoRA)** (gear icon) and **RL (GRPO)** (clipboard icon)
- Culminates in **SFT+RL Training Phase** (brain icon with neural network)
- **Inference Phase**:
- 4-Hop and 5-Hop diagrams show increased complexity
- Edge colors shift from red (training) to blue/green (inference)
- Node density increases with hop count
- **KG-Path Section**:
- Located at the bottom center
- Combines checklist (structured knowledge) and gear (reward mechanism)
- Suggests integration of knowledge graphs with reinforcement learning
---
### Key Observations
1. **Phase Separation**:
- Training focuses on short-hop reasoning (1-3 hops)
- Inference handles longer, more complex tasks (4-5 hops)
2. **Progression Indicators**:
- Node colors shift from pink (training) to light green (inference)
- Edge colors transition from red (training) to blue/green (inference)
3. **Reward Mechanism**:
- KG-Path Inspired + correctness reward signal appears as a foundational component
- Positioned below the SFT+RL phase, suggesting it underpins the training process
4. **Generalization Claim**:
- Explicitly states improved performance on "unseen 4/5 hop tasks"
- Implies the model can extrapolate beyond training data
---
### Interpretation
This diagram demonstrates a hierarchical approach to reasoning model development:
1. **Training Foundation**: Short-hop reasoning (1-3 hops) is established through base model fine-tuning (SFT) and reinforcement learning (RL).
2. **Advanced Training**: The SFT+RL phase combines these methods with knowledge graph-inspired paths and correctness rewards to build robust reasoning capabilities.
3. **Inference Capability**: The model generalizes to longer, unseen reasoning tasks (4-5 hops), suggesting effective transfer learning from the training phase.
The KG-Path Inspired component appears critical, likely enabling the model to leverage structured knowledge graphs during both training and inference. The color-coded progression visually reinforces the transition from simple to complex reasoning tasks, while the explicit mention of "unseen" tasks highlights the model's generalization potential.