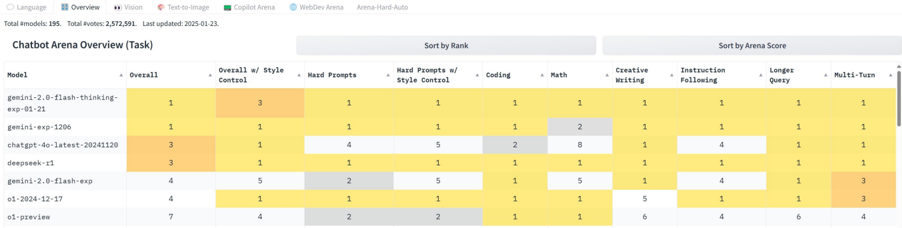
## Heatmap: Chatbot Arena Overview (Task)
### Overview
The image is a heatmap displaying the performance of various chatbot models across different tasks and metrics. The models are listed on the left, and the tasks/metrics are listed across the top. The cells are colored based on the model's performance in each category, with darker shades indicating better performance. The data includes overall rankings, performance on specific tasks like coding and math, and style-related metrics.
### Components/Axes
* **Title:** Chatbot Arena Overview (Task)
* **X-Axis (Columns):**
* Model
* Overall
* Overall w/ Style Control
* Hard Prompts
* Hard Prompts w/ Style Control
* Coding
* Math
* Creative Writing
* Instruction Following
* Longer Query
* Multi-Turn
* **Y-Axis (Rows):**
* gemini-2.0-flash-thinking-exp-01-21
* gemini-exp-1206
* chatgpt-4o-latest-20241120
* deepseek-t1
* gemini-2.0-flash-exp
* o1-2024-12-17
* o1-preview
* **Color Scale:** The heatmap uses a color scale where darker shades (likely yellow/orange) indicate better performance (lower numerical rank). Lighter shades (likely gray/white) indicate worse performance (higher numerical rank).
### Detailed Analysis or ### Content Details
Here's a breakdown of the data for each model across the different categories:
* **gemini-2.0-flash-thinking-exp-01-21:**
* Overall: 1
* Overall w/ Style Control: 3
* Hard Prompts: 1
* Hard Prompts w/ Style Control: 1
* Coding: 1
* Math: 1
* Creative Writing: 1
* Instruction Following: 1
* Longer Query: 1
* Multi-Turn: 1
* **gemini-exp-1206:**
* Overall: 1
* Overall w/ Style Control: 1
* Hard Prompts: 1
* Hard Prompts w/ Style Control: 1
* Coding: 1
* Math: 2
* Creative Writing: 1
* Instruction Following: 1
* Longer Query: 1
* Multi-Turn: 1
* **chatgpt-4o-latest-20241120:**
* Overall: 3
* Overall w/ Style Control: 1
* Hard Prompts: 4
* Hard Prompts w/ Style Control: 5
* Coding: 2
* Math: 8
* Creative Writing: 1
* Instruction Following: 4
* Longer Query: 1
* Multi-Turn: 1
* **deepseek-t1:**
* Overall: 3
* Overall w/ Style Control: 1
* Hard Prompts: 1
* Hard Prompts w/ Style Control: 1
* Coding: 1
* Math: 1
* Creative Writing: 1
* Instruction Following: 1
* Longer Query: 1
* Multi-Turn: 1
* **gemini-2.0-flash-exp:**
* Overall: 4
* Overall w/ Style Control: 5
* Hard Prompts: 2
* Hard Prompts w/ Style Control: 5
* Coding: 1
* Math: 5
* Creative Writing: 1
* Instruction Following: 4
* Longer Query: 1
* Multi-Turn: 3
* **o1-2024-12-17:**
* Overall: 4
* Overall w/ Style Control: 1
* Hard Prompts: 1
* Hard Prompts w/ Style Control: 1
* Coding: 1
* Math: 1
* Creative Writing: 5
* Instruction Following: 1
* Longer Query: 1
* Multi-Turn: 3
* **o1-preview:**
* Overall: 7
* Overall w/ Style Control: 4
* Hard Prompts: 2
* Hard Prompts w/ Style Control: 2
* Coding: 1
* Math: 1
* Creative Writing: 6
* Instruction Following: 4
* Longer Query: 6
* Multi-Turn: 4
### Key Observations
* The models "gemini-2.0-flash-thinking-exp-01-21" and "gemini-exp-1206" generally perform very well, consistently ranking at the top (rank 1) across most categories.
* "chatgpt-4o-latest-20241120" shows a weaker performance in "Hard Prompts" (rank 4), "Hard Prompts w/ Style Control" (rank 5), and "Math" (rank 8) compared to other categories.
* "o1-preview" has the lowest overall ranking (rank 7) and performs relatively worse in "Creative Writing" (rank 6) and "Longer Query" (rank 6).
### Interpretation
The heatmap provides a comparative overview of chatbot model performance across various tasks. The data suggests that some models excel in specific areas while others offer more consistent performance across the board. For example, while "chatgpt-4o-latest-20241120" performs well in most categories, it struggles with math and hard prompts. "gemini-2.0-flash-thinking-exp-01-21" and "gemini-exp-1206" appear to be the most consistently high-performing models based on this data. The "o1-preview" model seems to have the weakest overall performance. The data can be used to identify the strengths and weaknesses of each model and to select the most appropriate model for a given task.