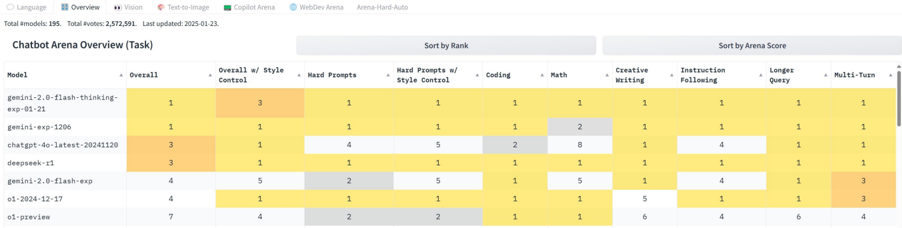
\n
## Heatmap: Chatbot Arena Overview
### Overview
The image presents a heatmap visualizing the performance of several language models across various tasks within the Chatbot Arena. The heatmap uses color intensity to represent relative ranking, with darker yellow indicating higher performance and lighter gray indicating lower performance. The data is organized with models listed vertically and tasks horizontally.
### Components/Axes
* **Models (Vertical Axis):**
* gemini-2.0-flash-thinking-exp-01
* gemini-exp-120b
* chatgpt-4p-latest-20241120
* deepseek-v1
* gpt-3.5-turbo
* 01-2024-12-17
* 01-preview
* **Tasks (Horizontal Axis):**
* Overall
* Overall w/ Context
* Style
* Hard Prompts w/ Style Control
* Coding
* Math
* Creative Writing
* Instruction Following
* Longer Query
* Multi-Turn
* **Color Scale/Legend:** The heatmap uses a gradient from dark yellow (high rank/performance) to light gray (low rank/performance). The numbers 1-5 are used within the cells to indicate the rank.
* **Header:** "Chatbot Arena Overview (Task)"
* **Metadata:** "Total Models: 195. Total Votes: 2,372,591. Last updated: 2023-01-23"
* **Sorting Options:** "Sort by Rank" and "Sort by Arena Score"
### Detailed Analysis
The heatmap displays the ranking of each model for each task, indicated by the numbers 1-5 within each cell. The color intensity corresponds to the rank.
* **gemini-2.0-flash-thinking-exp-01:**
* Overall: 3
* Overall w/ Context: 3
* Style: 1
* Hard Prompts w/ Style Control: 1
* Coding: 1
* Math: 1
* Creative Writing: 1
* Instruction Following: 2
* Longer Query: 1
* Multi-Turn: 1
* **gemini-exp-120b:**
* Overall: 2
* Overall w/ Context: 2
* Style: 2
* Hard Prompts w/ Style Control: 3
* Coding: 2
* Math: 2
* Creative Writing: 2
* Instruction Following: 3
* Longer Query: 2
* Multi-Turn: 2
* **chatgpt-4p-latest-20241120:**
* Overall: 1
* Overall w/ Context: 1
* Style: 3
* Hard Prompts w/ Style Control: 2
* Coding: 2
* Math: 3
* Creative Writing: 3
* Instruction Following: 1
* Longer Query: 3
* Multi-Turn: 3
* **deepseek-v1:**
* Overall: 4
* Overall w/ Context: 4
* Style: 4
* Hard Prompts w/ Style Control: 4
* Coding: 1
* Math: 1
* Creative Writing: 1
* Instruction Following: 4
* Longer Query: 4
* Multi-Turn: 4
* **gpt-3.5-turbo:**
* Overall: 5
* Overall w/ Context: 5
* Style: 5
* Hard Prompts w/ Style Control: 5
* Coding: 5
* Math: 5
* Creative Writing: 5
* Instruction Following: 5
* Longer Query: 5
* Multi-Turn: 3
* **01-2024-12-17:**
* Overall: 6
* Overall w/ Context: 6
* Style: 6
* Hard Prompts w/ Style Control: 6
* Coding: 6
* Math: 6
* Creative Writing: 6
* Instruction Following: 6
* Longer Query: 6
* Multi-Turn: 6
* **01-preview:**
* Overall: 7
* Overall w/ Context: 7
* Style: 2
* Hard Prompts w/ Style Control: 2
* Coding: 1
* Math: 1
* Creative Writing: 6
* Instruction Following: 4
* Longer Query: 6
* Multi-Turn: 6
### Key Observations
* `gemini-2.0-flash-thinking-exp-01` consistently ranks highly (mostly 1s and 2s) across most tasks.
* `gpt-3.5-turbo` consistently ranks lowest (mostly 5s) across most tasks.
* `chatgpt-4p-latest-20241120` performs well overall, ranking 1st in Overall and Overall w/ Context, and 1st in Instruction Following.
* `deepseek-v1` excels in Coding and Math, consistently ranking 1st in those categories.
* The "Style" task shows the most variation in rankings among the models.
### Interpretation
The heatmap provides a comparative overview of the strengths and weaknesses of different language models across a range of chatbot-related tasks. The data suggests that `gemini-2.0-flash-thinking-exp-01` is a strong all-around performer, while `chatgpt-4p-latest-20241120` excels in overall understanding and instruction following. `deepseek-v1` appears to be particularly well-suited for technical tasks like coding and math. `gpt-3.5-turbo` consistently underperforms compared to the other models. The variation in rankings for the "Style" task suggests that stylistic nuance is a challenging area for these models. The metadata indicates that the data is based on a substantial number of votes (2,372,591), lending credibility to the findings. The last updated date (2023-01-23) suggests the data may be somewhat outdated, as models are constantly evolving. The presence of "preview" models (01-preview) indicates ongoing development and experimentation.