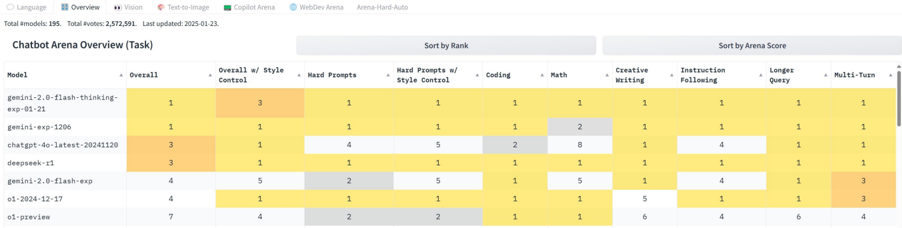
## Table: Chatbot Arena Overview (Task)
### Overview
The image displays a tabular dataset titled "Chatbot Arena Overview (Task)" with 7 rows (models) and 9 columns (performance metrics). The table uses color-coded cells (yellow, orange, gray) to represent rankings or scores, though no explicit legend is visible. The data is organized to compare models across categories like "Overall," "Coding," "Math," and "Creative Writing."
### Components/Axes
- **Headers**:
- Model (leftmost column)
- Overall
- Overall w/ Style Control
- Hard Prompts
- Hard Prompts w/ Style Control
- Coding
- Math
- Creative Writing
- Instruction Following
- Longer Query
- Multi-Turn
- **Rows**:
- gemini-2.0-flash-thinking-exp-01-21
- gemini-exp-1206
- chatgpt-4o-latest-20241120
- deepseek-r1
- gemini-2.0-flash-exp
- o1-2024-12-17
- o1-preview
- **Top Bar Text**:
- "Total #models: 195. Total #votes: 2,572,591. Last updated: 2025-01-23."
### Detailed Analysis
- **Model: gemini-2.0-flash-thinking-exp-01-21**
- Overall: 1 (yellow)
- Overall w/ Style Control: 3 (orange)
- Hard Prompts: 1 (yellow)
- Hard Prompts w/ Style Control: 1 (yellow)
- Coding: 1 (yellow)
- Math: 1 (yellow)
- Creative Writing: 1 (yellow)
- Instruction Following: 1 (yellow)
- Longer Query: 1 (yellow)
- Multi-Turn: 1 (yellow)
- **Model: gemini-exp-1206**
- Overall: 1 (yellow)
- Overall w/ Style Control: 1 (yellow)
- Hard Prompts: 1 (yellow)
- Hard Prompts w/ Style Control: 1 (yellow)
- Coding: 1 (yellow)
- Math: 2 (orange)
- Creative Writing: 1 (yellow)
- Instruction Following: 1 (yellow)
- Longer Query: 1 (yellow)
- Multi-Turn: 1 (yellow)
- **Model: chatgpt-4o-latest-20241120**
- Overall: 3 (orange)
- Overall w/ Style Control: 1 (yellow)
- Hard Prompts: 4 (orange)
- Hard Prompts w/ Style Control: 5 (orange)
- Coding: 2 (orange)
- Math: 8 (orange)
- Creative Writing: 1 (yellow)
- Instruction Following: 4 (orange)
- Longer Query: 1 (yellow)
- Multi-Turn: 1 (yellow)
- **Model: deepseek-r1**
- Overall: 3 (orange)
- Overall w/ Style Control: 1 (yellow)
- Hard Prompts: 1 (yellow)
- Hard Prompts w/ Style Control: 1 (yellow)
- Coding: 1 (yellow)
- Math: 1 (yellow)
- Creative Writing: 1 (yellow)
- Instruction Following: 1 (yellow)
- Longer Query: 1 (yellow)
- Multi-Turn: 1 (yellow)
- **Model: gemini-2.0-flash-exp**
- Overall: 4 (orange)
- Overall w/ Style Control: 5 (orange)
- Hard Prompts: 2 (orange)
- Hard Prompts w/ Style Control: 5 (orange)
- Coding: 1 (yellow)
- Math: 5 (orange)
- Creative Writing: 1 (yellow)
- Instruction Following: 4 (orange)
- Longer Query: 1 (yellow)
- Multi-Turn: 3 (orange)
- **Model: o1-2024-12-17**
- Overall: 4 (orange)
- Overall w/ Style Control: 1 (yellow)
- Hard Prompts: 1 (yellow)
- Hard Prompts w/ Style Control: 1 (yellow)
- Coding: 1 (yellow)
- Math: 1 (yellow)
- Creative Writing: 5 (orange)
- Instruction Following: 1 (yellow)
- Longer Query: 1 (yellow)
- Multi-Turn: 3 (orange)
- **Model: o1-preview**
- Overall: 7 (orange)
- Overall w/ Style Control: 4 (orange)
- Hard Prompts: 2 (orange)
- Hard Prompts w/ Style Control: 2 (orange)
- Coding: 1 (yellow)
- Math: 1 (yellow)
- Creative Writing: 6 (orange)
- Instruction Following: 4 (orange)
- Longer Query: 6 (orange)
- Multi-Turn: 4 (orange)
### Key Observations
1. **Highest Overall Scores**:
- "o1-preview" has the highest "Overall" score (7), followed by "o1-2024-12-17" and "gemini-2.0-flash-exp" (both 4).
2. **Math Performance**:
- "chatgpt-4o-latest-20241120" scores 8 in "Math," significantly higher than others (max 5 for "gemini-2.0-flash-exp").
3. **Style Control Impact**:
- "gemini-2.0-flash-thinking-exp-01-21" and "gemini-2.0-flash-exp" show improved scores with style control (e.g., "Overall w/ Style Control" increases from 1 to 3 and 1 to 5, respectively).
4. **Creative Writing**:
- "o1-2024-12-17" and "o1-preview" have the highest scores (5 and 6, respectively).
### Interpretation
The table highlights performance disparities across models in specific tasks. For example:
- **Math Dominance**: "chatgpt-4o-latest-20241120" excels in math (8), suggesting specialized training or architecture for numerical reasoning.
- **Multi-Turn Complexity**: "o1-preview" and "o1-2024-12-17" perform well in multi-turn interactions (4 and 3, respectively), indicating robustness in maintaining context over extended conversations.
- **Style Control Benefits**: Models like "gemini-2.0-flash-thinking-exp-01-21" and "gemini-2.0-flash-exp" show significant improvements when style control is applied, implying that structured output formatting enhances performance in certain tasks.
The data suggests that no single model dominates all categories, emphasizing the importance of task-specific optimization. The "o1-preview" model, with the highest "Overall" score, may represent a balanced performer across multiple domains, while "chatgpt-4o-latest-20241120" specializes in math and coding.