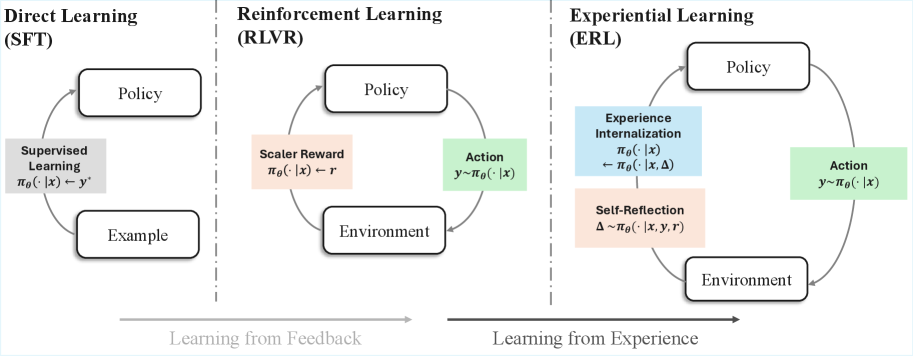
## Diagram: Comparison of Learning Paradigms (SFT, RLVR, ERL)
### Overview
The diagram illustrates three distinct learning frameworks: **Direct Learning (SFT)**, **Reinforcement Learning (RLVR)**, and **Experiential Learning (ERL)**. Each framework is represented as a cyclical system involving a **Policy**, **Environment**, and domain-specific mechanisms. Arrows indicate directional relationships, with labels describing processes like feedback loops, rewards, and internalization.
### Components/Axes
1. **Sections**:
- **Left (SFT)**: Direct Learning via Supervised Fine-Tuning.
- **Center (RLVR)**: Reinforcement Learning with Value Regularization.
- **Right (ERL)**: Experiential Learning emphasizing internalization and reflection.
2. **Key Elements**:
- **Policy**: Central node in all frameworks, representing decision-making rules.
- **Environment**: External context interacting with the Policy.
- **Arrows**: Denote causal or informational flow (e.g., "Learning from Feedback" spans SFT/RLVR; "Learning from Experience" spans ERL).
3. **Labels**:
- **SFT**:
- `πθ(·|x) ← y*` (Supervised Learning: Policy maps input `x` to supervised output `y*`).
- `πθ(·|x) ← Example` (Policy learns from labeled examples).
- **RLVR**:
- `πθ(·|x) ← r` (Scaler Reward: Policy maps input `x` to scalar reward `r`).
- `y∼πθ(·|x)` (Action: Policy generates action `y` from input `x`).
- **ERL**:
- `πθ(·|x) ← πθ(·|x,Δ)` (Experience Internalization: Policy updates using experience `Δ`).
- `Δ∼πθ(·|x,y,r)` (Self-Reflection: Experience `Δ` derived from action `y`, input `x`, and reward `r`).
### Detailed Analysis
- **SFT (Direct Learning)**:
- Policy is trained via **supervised learning** using labeled examples (`y*`).
- Feedback loop: Examples → Policy → Environment → Policy (closed loop).
- **RLVR (Reinforcement Learning)**:
- Policy interacts with the Environment to generate actions (`y∼πθ(·|x)`).
- Scaler rewards (`r`) shape Policy updates.
- Feedback loop: Environment → Reward → Policy → Environment.
- **ERL (Experiential Learning)**:
- Policy generates actions (`y∼πθ(·|x)`) and experiences (`Δ∼πθ(·|x,y,r)`).
- **Experience Internalization**: Policy refines itself using internalized experiences (`πθ(·|x) ← πθ(·|x,Δ)`).
- Self-reflection integrates input, action, and reward to update the Policy.
### Key Observations
1. **Feedback vs. Experience**:
- SFT and RLVR rely on **external feedback** (supervised labels or scalar rewards).
- ERL emphasizes **internalized experience** (self-generated `Δ`) for learning.
2. **Cyclical Nature**:
- All frameworks involve iterative Policy-Environment interactions.
- ERL introduces a unique self-reflection mechanism absent in SFT/RLVR.
3. **Notation Consistency**:
- Policy notation (`πθ(·|x)`) is consistent across frameworks, denoting parameterized mappings.
- Arrows explicitly differentiate between **input-driven** (SFT/RLVR) and **experience-driven** (ERL) learning.
### Interpretation
The diagram contrasts three learning paradigms:
- **SFT** represents traditional supervised learning, where Policies are rigidly trained on labeled data.
- **RLVR** introduces reward-driven adaptation, allowing Policies to optimize for scalar feedback in dynamic Environments.
- **ERL** shifts focus to **autonomous learning**, where Policies internalize experiences and reflect on past actions/rewards to improve.
The separation of "Learning from Feedback" (SFT/RLVR) and "Learning from Experience" (ERL) highlights a spectrum from externally guided to self-directed learning. ERL’s inclusion of **Experience Internalization** suggests a more holistic approach, where Policies evolve by synthesizing past interactions rather than relying solely on external signals. This aligns with theories of metacognition and adaptive systems in AI.
No numerical data or outliers are present; the diagram is purely conceptual, emphasizing structural differences between learning methodologies.