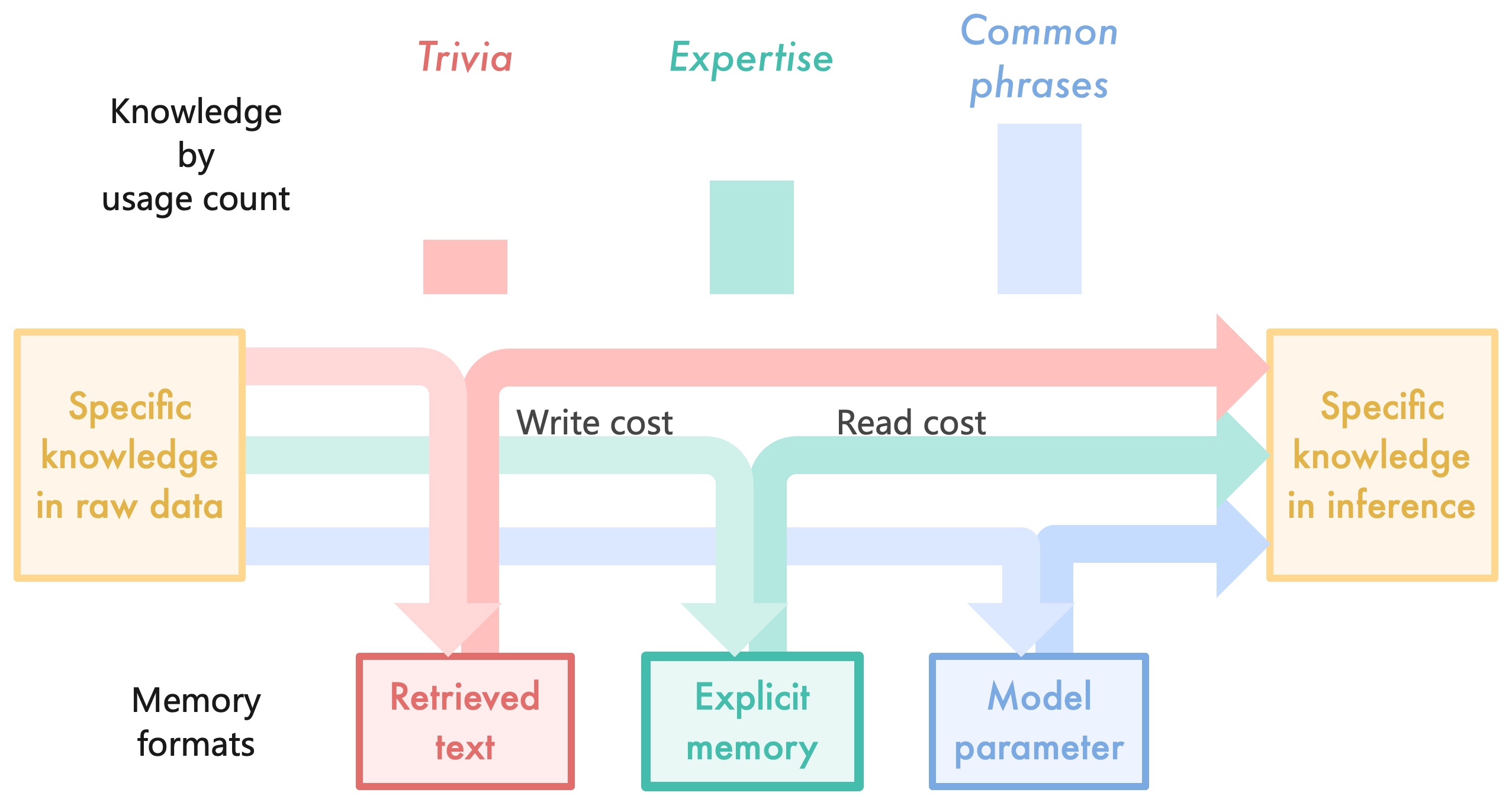
## Diagram: Knowledge Representation and Usage
### Overview
The image is a diagram illustrating how knowledge is represented and used, categorized by usage count. It shows the flow of information from "Specific knowledge in raw data" to "Specific knowledge in inference" through different pathways representing "Trivia," "Expertise," and "Common phrases." The diagram also highlights the "Write cost" and "Read cost" associated with different memory formats.
### Components/Axes
* **Title:** Knowledge by usage count
* **Source Node (Left):** Specific knowledge in raw data (contained in a light orange box)
* **Destination Node (Right):** Specific knowledge in inference (contained in a light orange box)
* **Memory Formats (Bottom Left):** Memory formats
* **Intermediate Nodes (Bottom):**
* Retrieved text (contained in a red box)
* Explicit memory (contained in a green box)
* Model parameter (contained in a blue box)
* **Categories (Top):**
* Trivia (red)
* Expertise (green)
* Common phrases (blue)
* **Arrows:** Represent the flow of information, colored according to the category.
* Red arrows: Trivia
* Green arrows: Expertise
* Blue arrows: Common phrases
* **Labels on Arrows:**
* Write cost (associated with Trivia and Expertise)
* Read cost (associated with Expertise and Common phrases)
### Detailed Analysis
* **Specific knowledge in raw data:** Located on the left side, represented by a light orange box.
* **Specific knowledge in inference:** Located on the right side, represented by a light orange box.
* **Trivia (Red):**
* A small red rectangle is positioned above the "Retrieved text" box, indicating the relative usage count of trivia.
* A red arrow originates from the "Specific knowledge in raw data" box, splits into two paths: one going down to "Retrieved text" and the other going directly to "Specific knowledge in inference."
* The arrow segment going from the split to "Retrieved text" is labeled "Write cost".
* **Expertise (Green):**
* A green rectangle is positioned above the "Explicit memory" box, indicating the relative usage count of expertise.
* A green arrow originates from the "Specific knowledge in raw data" box, splits into two paths: one going down to "Explicit memory" and the other going directly to "Specific knowledge in inference."
* The arrow segment going from the split to "Explicit memory" is labeled "Write cost".
* The arrow segment going from "Explicit memory" to "Specific knowledge in inference" is labeled "Read cost".
* **Common phrases (Blue):**
* A blue rectangle is positioned above the "Model parameter" box, indicating the relative usage count of common phrases.
* A blue arrow originates from the "Specific knowledge in raw data" box, goes down to "Model parameter" and then to "Specific knowledge in inference."
* The arrow segment going from "Model parameter" to "Specific knowledge in inference" is labeled "Read cost".
* **Memory Formats:** Located at the bottom, indicating the type of memory associated with each category.
* Retrieved text (red box)
* Explicit memory (green box)
* Model parameter (blue box)
### Key Observations
* The diagram illustrates the flow of knowledge from raw data to inference, categorized by usage count.
* Trivia has a direct path from raw data to inference and also involves retrieved text.
* Expertise involves explicit memory and has both write and read costs.
* Common phrases involve model parameters and have a read cost.
* The relative size of the rectangles above each category ("Trivia," "Expertise," "Common phrases") indicates the relative usage count, with "Common phrases" having the highest usage count, followed by "Expertise," and then "Trivia."
### Interpretation
The diagram suggests that different types of knowledge are processed and stored in different ways. Trivia is quickly retrieved and may not require extensive processing. Expertise requires more structured storage and processing, involving both writing to and reading from explicit memory. Common phrases are likely stored as model parameters, allowing for efficient retrieval during inference. The diagram highlights the trade-offs between different knowledge representation methods in terms of storage, processing cost, and usage frequency. The "Write cost" and "Read cost" labels suggest that there are computational or resource costs associated with storing and retrieving different types of knowledge. The relative heights of the "Trivia", "Expertise", and "Common phrases" blocks suggest the relative frequency of each type of knowledge.