## Diagram: Knowledge Processing Architecture
### Overview
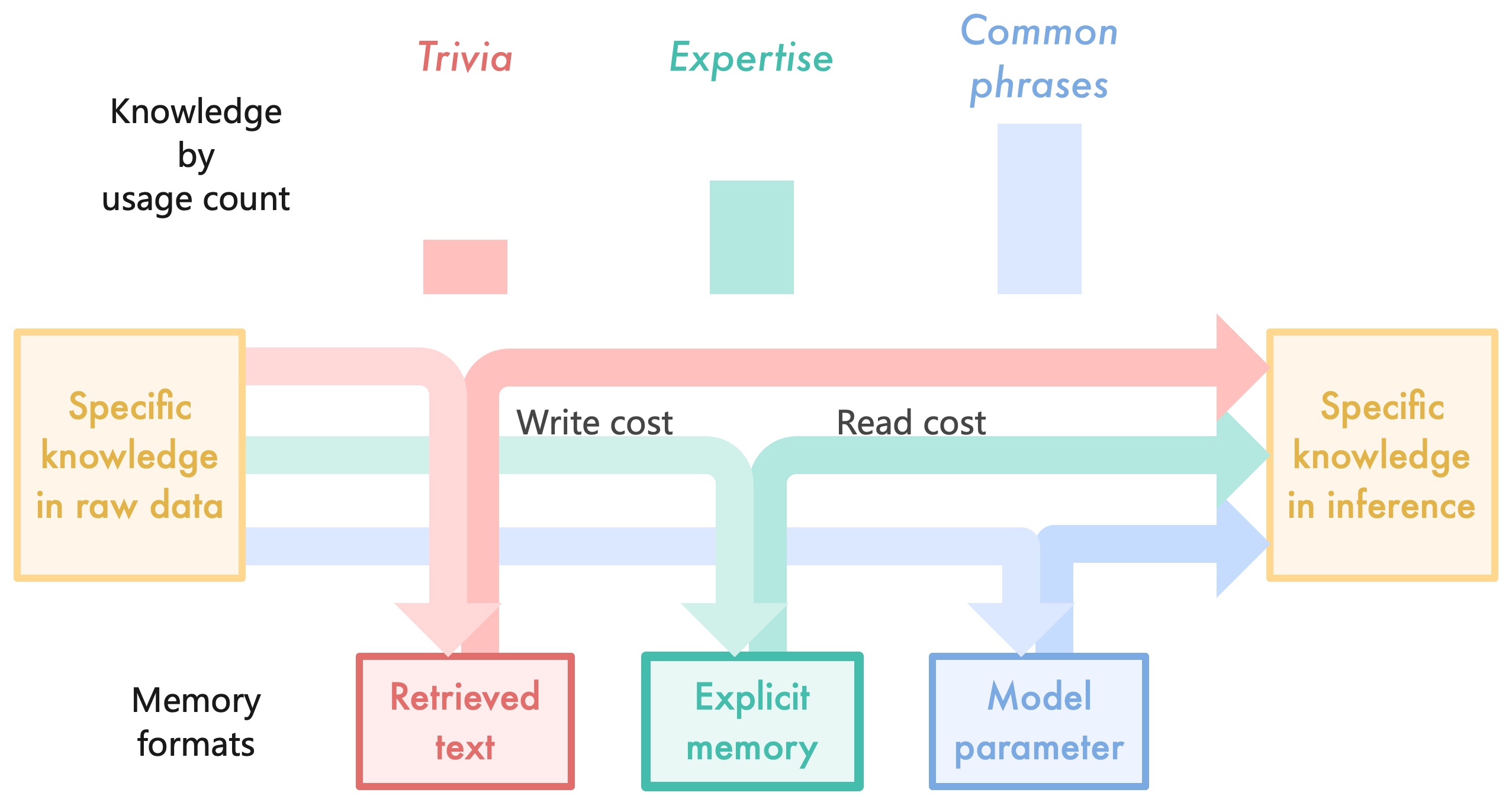
This diagram illustrates the flow of specific knowledge from raw data to inference through three memory formats: Retrieved text, Explicit memory, and Model parameter. It categorizes knowledge by usage frequency (Trivia, Expertise, Common phrases) and visualizes associated write/read costs.
### Components/Axes
- **Key Elements**:
- **Knowledge Types** (Trivia, Expertise, Common phrases) with usage count bars (pink, teal, blue)
- **Memory Formats**:
- Retrieved text (pink)
- Explicit memory (teal)
- Model parameter (blue)
- **Knowledge States**:
- Specific knowledge in raw data (left)
- Specific knowledge in inference (right)
- **Cost Indicators**:
- Write cost (pink arrow)
- Read cost (teal arrow)
- **Spatial Layout**:
- Top: Knowledge types with usage count bars
- Middle: Three memory format boxes connected by bidirectional arrows
- Bottom: Memory format labels
- Arrows color-coded to match knowledge types
### Detailed Analysis
1. **Knowledge Usage Distribution**:
- Trivia (pink): Smallest usage count bar
- Expertise (teal): Medium-sized bar
- Common phrases (blue): Largest bar
2. **Memory Format Connections**:
- **Retrieved text** (pink):
- Receives Trivia knowledge via write cost
- Feeds into inference via read cost
- **Explicit memory** (teal):
- Receives Expertise knowledge via write cost
- Feeds into inference via read cost
- **Model parameter** (blue):
- Receives Common phrases knowledge via write cost
- Feeds into inference via read cost
3. **Cost Relationships**:
- Write costs (arrows from raw data to memory formats)
- Read costs (arrows from memory formats to inference)
- Color-coded arrows match knowledge type colors
### Key Observations
- Common phrases dominate usage (largest bar) and directly influence model parameters
- Trivia knowledge has minimal usage but still requires both write/read pathways
- Expertise knowledge shows balanced usage and memory engagement
- All knowledge types converge on "specific knowledge in inference"
### Interpretation
This architecture suggests:
1. **Hierarchical Knowledge Processing**: More frequently used knowledge (Common phrases) becomes embedded in model parameters, while less common knowledge (Trivia) remains in retrieved text
2. **Cost Efficiency**: Explicit memory appears optimized for Expertise knowledge, balancing write/read costs
3. **Inference Integration**: All knowledge types ultimately contribute to inference, but through different pathways
4. **Scalability Implications**: The system design accommodates varying knowledge frequencies through specialized memory formats
The diagram emphasizes that knowledge processing efficiency depends on both usage frequency and memory format suitability, with model parameters serving as the primary repository for high-frequency knowledge.