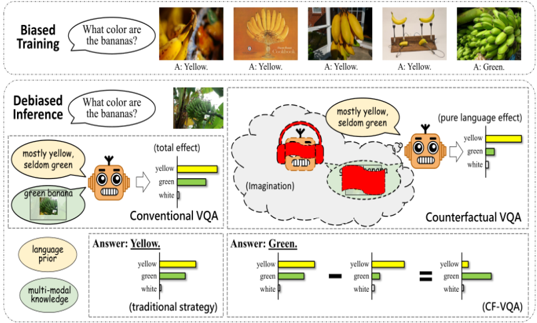
## Biased Training: Visual Question Answering (VQA)
### Overview
The image illustrates a comparison between biased training and debiased inference in the context of Visual Question Answering (VQA). It shows how different training strategies can affect the model's ability to accurately answer questions about images.
### Components/Axes
- **Training Strategies**: Biased training, Conventional VQA, Counterfactual VQA
- **Answer Categories**: Yellow, Green
- **Image Categories**: Yellow, Green
### Detailed Analysis or Content Details
- **Biased Training**: The model is trained on images with a bias towards the color yellow. This is evident from the images labeled "A. Yellow" and the corresponding answers.
- **Conventional VQA**: The model uses a traditional strategy and answers "Yellow" for the image category "Yellow."
- **Counterfactual VQA**: The model uses a counterfactual strategy and answers "Green" for the image category "Yellow."
### Key Observations
- The model exhibits a bias towards the color yellow in both biased training and conventional VQA.
- In counterfactual VQA, the model attempts to correct the bias by answering "Green" for the image category "Yellow."
### Interpretation
The data suggests that biased training can lead to models that are not only inaccurate but also perpetuate existing biases. The conventional VQA strategy, while straightforward, does not address the bias. The counterfactual VQA strategy, on the other hand, shows an attempt to correct the bias, but it may not fully eliminate it. This highlights the importance of debiased training and the need for strategies that can effectively correct biases in models.