\n
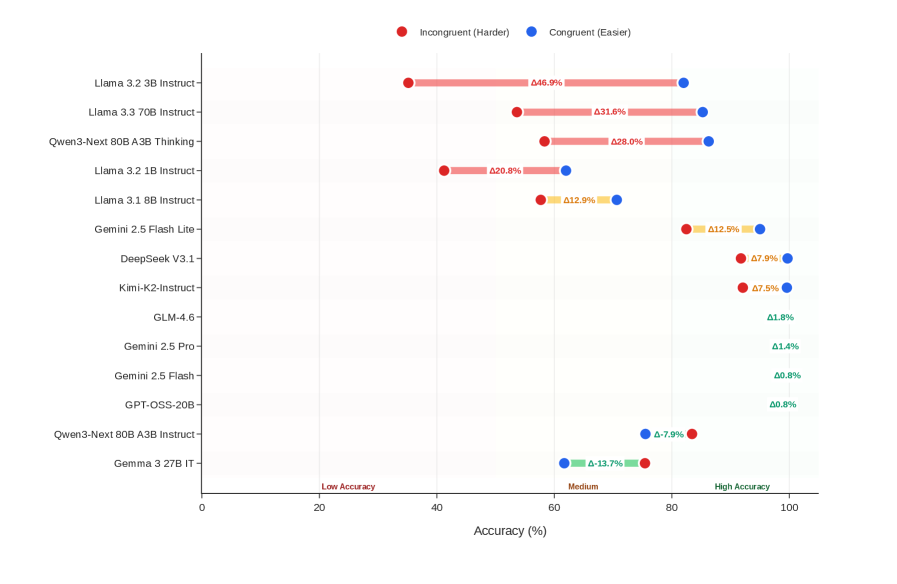
## Chart: Model Accuracy Comparison (Incongruent vs. Congruent)
### Overview
This chart compares the accuracy of several large language models (LLMs) on two different tasks: an "Incongruent (Harder)" task and a "Congruent (Easier)" task. Accuracy is represented as a percentage, with each model having two data points – one for each task – displayed as horizontal bars. The chart is a horizontal bar chart with models listed on the y-axis and accuracy percentage on the x-axis.
### Components/Axes
* **Y-axis (Vertical):** Lists the names of the LLMs being compared. The models are:
* Llama 3.2 3B Instruct
* Llama 3.3 70B Instruct
* Qwen-3 80B A3B Thinking
* Llama 3.2 1B Instruct
* Llama 3.1 8B Instruct
* Gemini 2.5 Flash Lite
* DeepSeek V3.1
* Kimi-K2-Instruct
* GLM-4.6
* Gemini 2.5 Pro
* Gemini 2.5 Flash
* GPT-QSS-20B
* Qwen-3-Next 80B A3B Instruct
* Gemma 3.2B IT
* **X-axis (Horizontal):** Represents Accuracy (%) ranging from 0 to 100. The axis is divided into three regions: "Low Accuracy" (0-40), "Medium" (40-80), and "High Accuracy" (80-100).
* **Legend (Top-Right):**
* Red Circle: Incongruent (Harder)
* Blue Circle: Congruent (Easier)
### Detailed Analysis
The chart displays accuracy percentages for each model on both tasks. The red bars represent the "Incongruent (Harder)" task, and the blue bars represent the "Congruent (Easier)" task.
Here's a breakdown of the accuracy values, reading from top to bottom:
* **Llama 3.2 3B Instruct:** Incongruent: ~66.9%, Congruent: ~93.6%
* **Llama 3.3 70B Instruct:** Incongruent: ~81.6%, Congruent: ~93.1%
* **Qwen-3 80B A3B Thinking:** Incongruent: ~68.0%, Congruent: ~92.8%
* **Llama 3.2 1B Instruct:** Incongruent: ~60.8%, Congruent: ~82.0%
* **Llama 3.1 8B Instruct:** Incongruent: ~62.9%, Congruent: ~81.2%
* **Gemini 2.5 Flash Lite:** Incongruent: ~62.5%, Congruent: ~81.2%
* **DeepSeek V3.1:** Incongruent: ~67.9%, Congruent: ~87.5%
* **Kimi-K2-Instruct:** Incongruent: ~67.5%, Congruent: ~87.8%
* **GLM-4.6:** Incongruent: ~61.8%, Congruent: ~81.8%
* **Gemini 2.5 Pro:** Incongruent: ~61.4%, Congruent: ~80.8%
* **Gemini 2.5 Flash:** Incongruent: ~50.8%, Congruent: ~80.8%
* **GPT-QSS-20B:** Incongruent: ~49.8%, Congruent: ~80.8%
* **Qwen-3-Next 80B A3B Instruct:** Incongruent: ~53.7%, Congruent: ~80.9%
* **Gemma 3.2B IT:** Incongruent: ~53.7%, Congruent: ~81.3%
### Key Observations
* All models perform significantly better on the "Congruent (Easier)" task than on the "Incongruent (Harder)" task.
* Llama 3.3 70B Instruct exhibits the highest accuracy on the "Incongruent (Harder)" task (~81.6%).
* The models with the lowest accuracy on the "Incongruent (Harder)" task are GPT-QSS-20B and Qwen-3-Next 80B A3B Instruct (~50%).
* The accuracy spread between the "Incongruent" and "Congruent" tasks appears relatively consistent across most models.
### Interpretation
The chart demonstrates a clear difference in performance between the LLMs depending on the task complexity. The "Incongruent (Harder)" task presents a greater challenge, resulting in lower accuracy scores across the board. This suggests that the models are more sensitive to task formulation or require more robust reasoning capabilities to handle incongruent information.
The consistent gap in accuracy between the two tasks indicates that the difficulty level is a primary driver of performance. The models that excel on the harder task (e.g., Llama 3.3 70B Instruct) likely possess stronger reasoning or problem-solving abilities.
The relatively narrow range of accuracy on the "Congruent (Easier)" task suggests that most of these models have reached a level of proficiency where they can handle simpler tasks with high accuracy. The focus for improvement may therefore be on enhancing their ability to tackle more complex and nuanced challenges, as represented by the "Incongruent (Harder)" task. The chart provides a valuable comparative analysis of these models, highlighting their strengths and weaknesses in different scenarios.