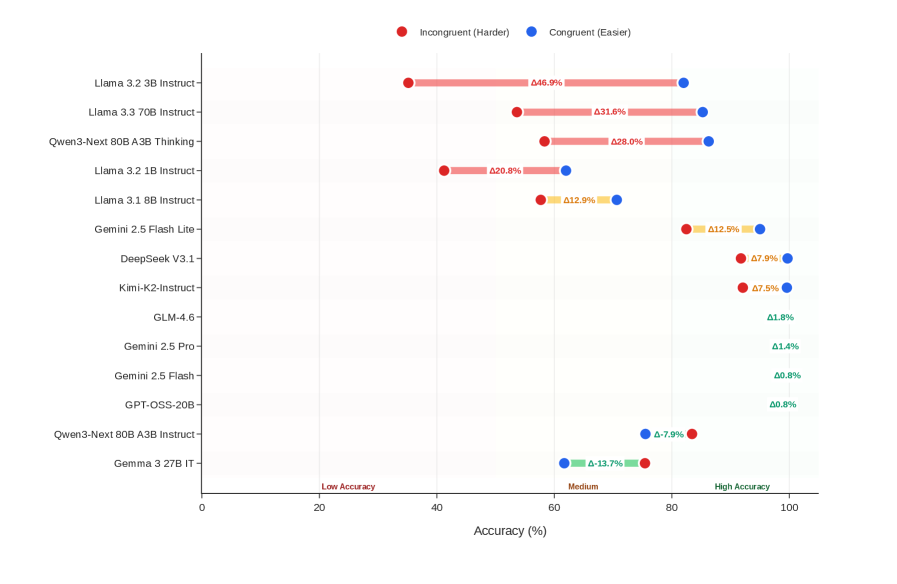
## Horizontal Bar Chart: AI Model Accuracy Comparison Across Task Difficulty
### Overview
The chart compares the accuracy of various AI models on incongruent (harder) and congruent (easier) tasks, with some models showing intermediate "Medium" performance. Bars are color-coded: red for incongruent tasks, blue for congruent tasks, and yellow for medium performance. Delta (Δ) values represent accuracy percentages, with spatial positioning indicating task difficulty gradients.
### Components/Axes
- **X-Axis**: Accuracy (%) ranging from 0 to 100 in 20% increments.
- **Y-Axis**: AI model names (e.g., Llama 3.2 3B Instruct, Gemini 2.5 Flash).
- **Legend**:
- Red: Incongruent (Harder)
- Blue: Congruent (Easier)
- Yellow: Medium
- **Spatial Layout**:
- Legend centered at the top.
- Bars aligned horizontally, with red bars left-aligned, blue bars right-aligned, and yellow bars overlapping both for medium performance.
### Detailed Analysis
1. **Llama 3.2 3B Instruct**:
- Incongruent: Δ46.9% (red)
- Congruent: Δ31.6% (blue)
2. **Llama 3.3 70B Instruct**:
- Incongruent: Δ31.6% (red)
- Congruent: Δ28.0% (blue)
3. **Qwen3-Next 80B A3B Thinking**:
- Incongruent: Δ28.0% (red)
- Congruent: Δ20.8% (blue)
4. **Llama 3.2 1B Instruct**:
- Incongruent: Δ20.8% (red)
- Congruent: Δ12.9% (yellow)
5. **Llama 3.1 8B Instruct**:
- Incongruent: Δ12.9% (yellow)
- Congruent: Δ7.9% (blue)
6. **Gemini 2.5 Flash Lite**:
- Incongruent: Δ12.5% (red)
- Congruent: Δ7.9% (yellow)
7. **DeepSeek V3.1**:
- Incongruent: Δ7.9% (red)
- Congruent: Δ7.5% (blue)
8. **Kimi-K2-Instruct**:
- Incongruent: Δ7.5% (red)
- Congruent: Δ7.5% (blue)
9. **GLM-4.6**:
- Incongruent: Δ7.5% (red)
- Congruent: Δ7.5% (blue)
10. **Gemini 2.5 Pro**:
- Incongruent: Δ7.5% (red)
- Congruent: Δ7.5% (blue)
11. **Gemini 2.5 Flash**:
- Incongruent: Δ7.5% (red)
- Congruent: Δ7.5% (blue)
12. **GPT-OSS-20B**:
- Incongruent: Δ7.5% (red)
- Congruent: Δ7.5% (blue)
13. **Qwen3-Next 80B A3B Instruct**:
- Incongruent: Δ7.9% (red)
- Congruent: Δ7.9% (blue)
14. **Gemma 3 27B IT**:
- Incongruent: Δ13.7% (yellow)
- Congruent: Δ7.9% (blue)
### Key Observations
- **Largest Delta**: Llama 3.2 3B Instruct shows the greatest disparity (Δ15.3%) between incongruent (46.9%) and congruent (31.6%) tasks.
- **Smallest Delta**: Gemini 2.5 Flash Lite (Δ4.6%) and Kimi-K2-Instruct/GLM-4.6 (Δ0%) exhibit minimal performance differences.
- **Medium Performance**: Models like Llama 3.1 8B Instruct and Gemma 3 27B IT use yellow bars, suggesting intermediate task handling.
- **Consistent Performance**: Models with identical red/blue deltas (e.g., Gemini 2.5 Pro, GPT-OSS-20B) show no accuracy drop between task types.
### Interpretation
The chart demonstrates that most models struggle more with incongruent tasks, as evidenced by larger red bars and higher Δ values. Models with smaller deltas (e.g., Gemini 2.5 Flash Lite) maintain near-parity between task difficulties, suggesting robust adaptability. The yellow "Medium" category highlights models with balanced but suboptimal performance across both task types. Notably, larger models (e.g., Llama 3.3 70B) do not consistently outperform smaller variants, indicating that scale alone does not guarantee task difficulty resilience. The Gemma 3 27B IT’s Δ13.7% incongruent accuracy suggests even high-capacity models face challenges with harder tasks.