## Bar Chart: Accuracy Comparison
### Overview
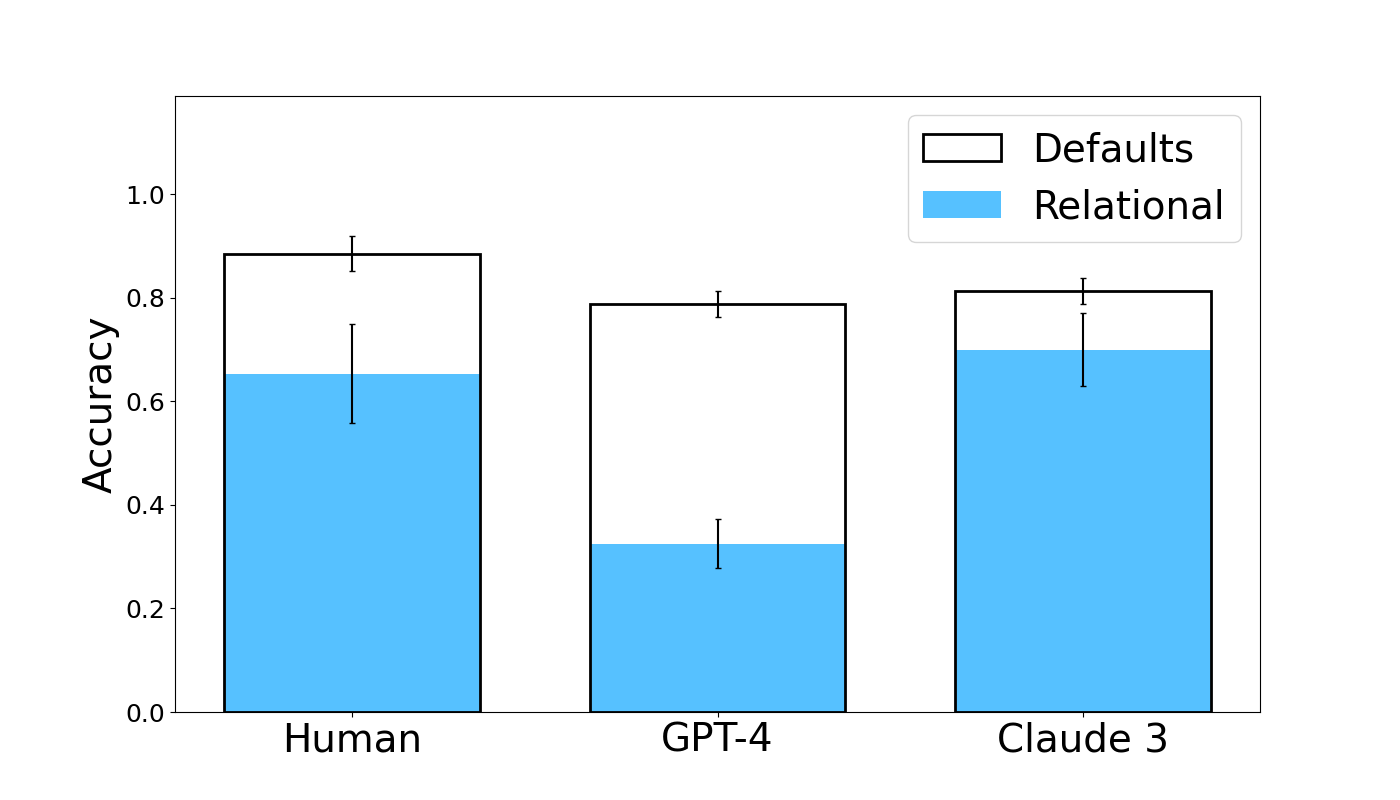
The image is a bar chart comparing the accuracy of "Defaults" and "Relational" approaches across three categories: Human, GPT-4, and Claude 3. The chart displays accuracy on the y-axis, ranging from 0.0 to 1.0. Each category (Human, GPT-4, Claude 3) has two bars representing the "Defaults" and "Relational" approaches. Error bars are included on each bar.
### Components/Axes
* **Y-axis:** "Accuracy", ranging from 0.0 to 1.0 in increments of 0.2.
* **X-axis:** Categories: Human, GPT-4, Claude 3.
* **Legend (Top-Right):**
* "Defaults": Represented by a white bar with a black outline.
* "Relational": Represented by a light blue bar.
### Detailed Analysis
Here's a breakdown of the accuracy values for each category and approach:
* **Human:**
* Relational (Light Blue): Accuracy is approximately 0.65, with an error bar extending from approximately 0.55 to 0.75.
* Defaults (White): The total height of the bar is approximately 0.89, so the Defaults accuracy is approximately 0.89 - 0.65 = 0.24. The error bar extends from approximately 0.8 to 0.95.
* **GPT-4:**
* Relational (Light Blue): Accuracy is approximately 0.32, with an error bar extending from approximately 0.25 to 0.40.
* Defaults (White): The total height of the bar is approximately 0.79, so the Defaults accuracy is approximately 0.79 - 0.32 = 0.47. The error bar extends from approximately 0.75 to 0.82.
* **Claude 3:**
* Relational (Light Blue): Accuracy is approximately 0.70, with an error bar extending from approximately 0.65 to 0.78.
* Defaults (White): The total height of the bar is approximately 0.82, so the Defaults accuracy is approximately 0.82 - 0.70 = 0.12. The error bar extends from approximately 0.78 to 0.85.
### Key Observations
* For Human and Claude 3, the "Relational" approach has a higher accuracy than for GPT-4.
* For GPT-4, the "Relational" approach has a lower accuracy than for Human and Claude 3.
* The "Defaults" approach has a higher accuracy for GPT-4 than for Human and Claude 3.
### Interpretation
The bar chart compares the accuracy of "Defaults" and "Relational" approaches across Human, GPT-4, and Claude 3. The data suggests that the "Relational" approach is more effective for Human and Claude 3, while the "Defaults" approach is more effective for GPT-4. This could indicate that GPT-4 benefits more from the default settings, while Human and Claude 3 benefit from a relational approach. The error bars provide a measure of the variability in the data, which should be considered when interpreting the results.