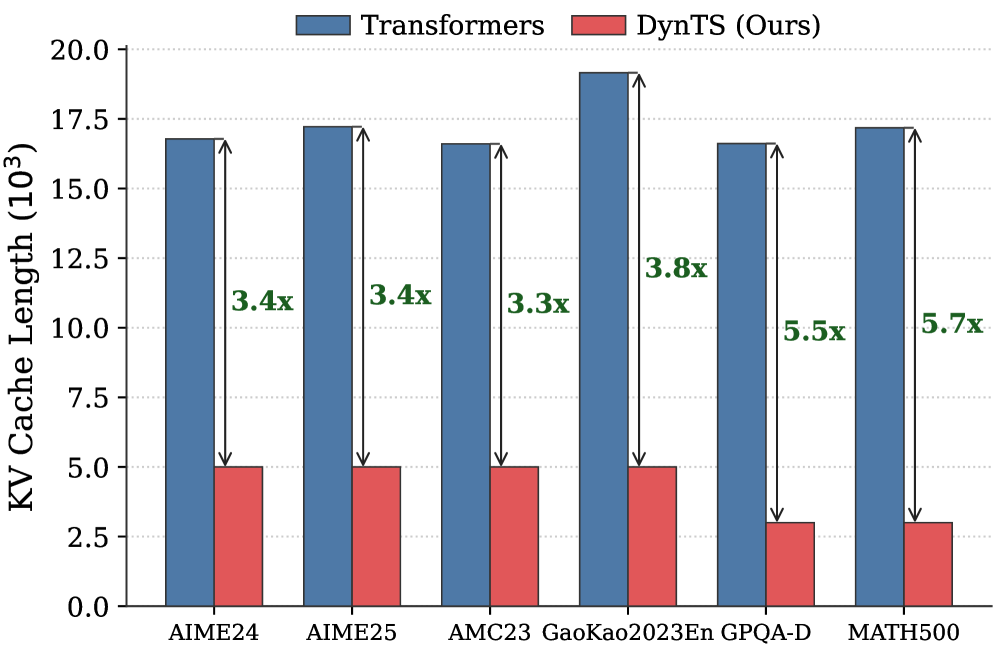
## Bar Chart: KV Cache Length Comparison - Transformers vs. DynTS
### Overview
This bar chart compares the KV Cache Length (in 10^3 units) achieved by two models, "Transformers" and "DynTS (Ours)", across six different datasets: AIME24, AIME25, AMC23, GaoKao2023En, GPQA-D, and MATH500. The chart visually represents the performance difference in terms of KV cache length, with "DynTS" consistently achieving significantly shorter cache lengths. Above each "DynTS" bar is a multiplier indicating how much shorter the cache length is compared to the "Transformers" model.
### Components/Axes
* **X-axis:** Dataset names: AIME24, AIME25, AMC23, GaoKao2023En, GPQA-D, MATH500.
* **Y-axis:** KV Cache Length (10^3). Scale ranges from 0.0 to 20.0, with increments of 2.5.
* **Legend:**
* Blue: Transformers
* Red: DynTS (Ours)
* **Labels:** Each "DynTS" bar has a label indicating the speedup factor (e.g., "3.4x", "3.8x").
### Detailed Analysis
The chart consists of paired bars for each dataset, representing the KV Cache Length for Transformers and DynTS.
* **AIME24:**
* Transformers: Approximately 16.5 (10^3)
* DynTS: Approximately 4.8 (10^3). Speedup: 3.4x
* **AIME25:**
* Transformers: Approximately 17.5 (10^3)
* DynTS: Approximately 5.0 (10^3). Speedup: 3.4x
* **AMC23:**
* Transformers: Approximately 16.8 (10^3)
* DynTS: Approximately 5.0 (10^3). Speedup: 3.3x
* **GaoKao2023En:**
* Transformers: Approximately 19.0 (10^3)
* DynTS: Approximately 5.0 (10^3). Speedup: 3.8x
* **GPQA-D:**
* Transformers: Approximately 16.5 (10^3)
* DynTS: Approximately 3.0 (10^3). Speedup: 5.5x
* **MATH500:**
* Transformers: Approximately 17.0 (10^3)
* DynTS: Approximately 3.0 (10^3). Speedup: 5.7x
The "Transformers" bars are consistently taller than the "DynTS" bars across all datasets. The speedup factors above the "DynTS" bars indicate the magnitude of the reduction in KV Cache Length.
### Key Observations
* "DynTS" consistently achieves a significantly shorter KV Cache Length compared to "Transformers" across all datasets.
* The speedup factor varies between 3.3x and 5.7x.
* The largest speedup is observed on the GPQA-D and MATH500 datasets (5.5x and 5.7x respectively).
* The KV Cache Length for "Transformers" remains relatively stable across all datasets, fluctuating between approximately 16.5 and 19.0 (10^3).
### Interpretation
The data demonstrates that the "DynTS (Ours)" model is substantially more efficient in terms of KV Cache Length compared to the "Transformers" model. This suggests that "DynTS" requires less memory to store the KV cache, which is a critical factor in the performance of large language models, especially when dealing with long sequences. The varying speedup factors indicate that the benefits of "DynTS" are dataset-dependent, with larger improvements observed on datasets like GPQA-D and MATH500. The relatively stable KV Cache Length for "Transformers" suggests that its memory usage is less sensitive to the specific dataset. The consistent reduction in KV Cache Length by DynTS indicates a fundamental architectural advantage in managing memory usage during processing. This could translate to faster inference speeds and the ability to handle longer sequences with the same hardware resources.