## Bar Chart: Jailbreak Evaluations
### Overview
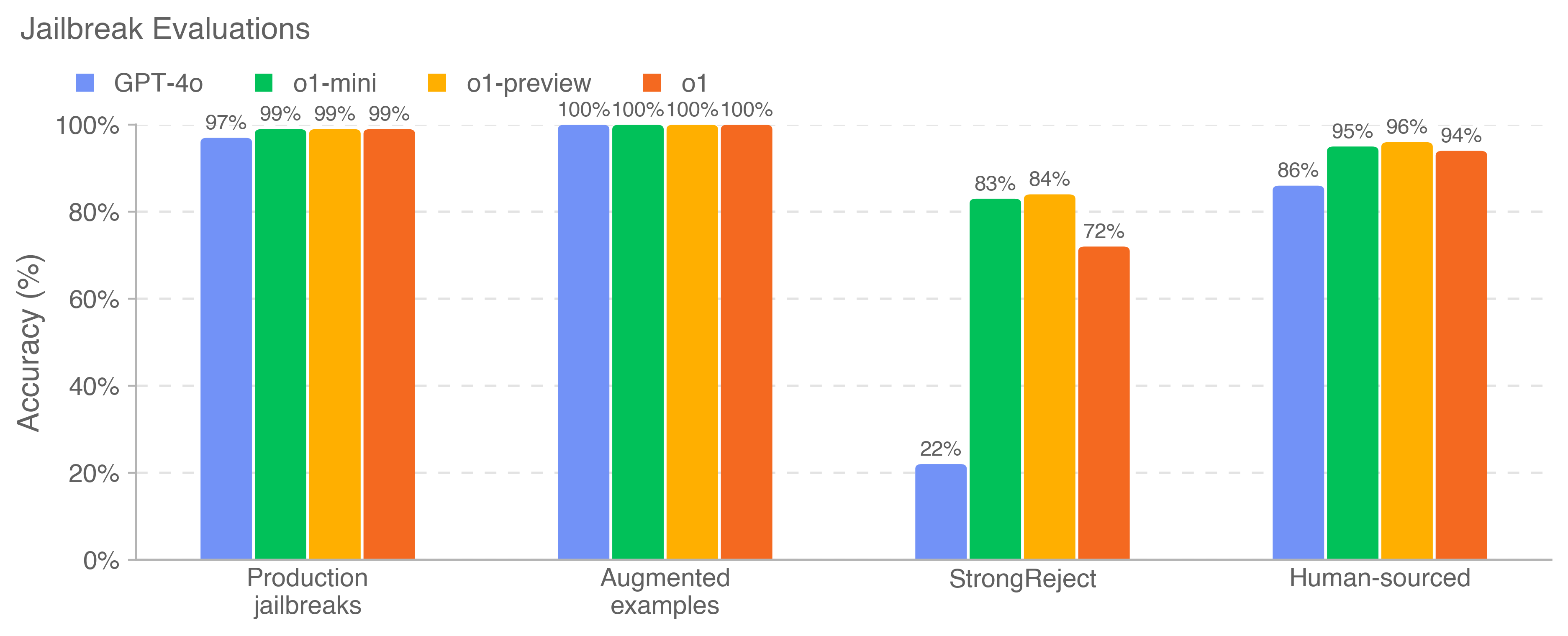
The chart compares the accuracy of four AI models (GPT-4o, o1-mini, o1-preview, o1) across four jailbreak evaluation categories: Production jailbreaks, Augmented examples, StrongReject, and Human-sourced. Accuracy is measured as a percentage from 0% to 100%.
### Components/Axes
- **X-axis**: Jailbreak categories (Production jailbreaks, Augmented examples, StrongReject, Human-sourced)
- **Y-axis**: Accuracy (%) with increments at 0%, 20%, 40%, 60%, 80%, 100%
- **Legend**: Located at top-left, mapping colors to models:
- Blue: GPT-4o
- Green: o1-mini
- Orange: o1-preview
- Red: o1
### Detailed Analysis
1. **Production jailbreaks**:
- GPT-4o: 97%
- o1-mini: 99%
- o1-preview: 99%
- o1: 99%
2. **Augmented examples**:
- All models: 100% accuracy
3. **StrongReject**:
- GPT-4o: 22%
- o1-mini: 83%
- o1-preview: 84%
- o1: 72%
4. **Human-sourced**:
- GPT-4o: 86%
- o1-mini: 95%
- o1-preview: 96%
- o1: 94%
### Key Observations
- **High performance in standard categories**: All models achieve near-perfect accuracy (97-100%) in Production jailbreaks and Augmented examples.
- **Significant drop in StrongReject**: GPT-4o performs poorly (22%), while other models maintain moderate accuracy (72-84%).
- **Human-sourced improvement**: All models show increased accuracy compared to StrongReject, with o1-preview leading at 96%.
### Interpretation
The data reveals a critical vulnerability in AI models' ability to handle "StrongReject" jailbreaks, where GPT-4o's accuracy plummets to 22%. This suggests current models struggle with highly resistant jailbreak scenarios. The near-perfect performance in standard categories indicates robust training on common jailbreak patterns, but the disparity in StrongReject performance highlights a need for improved adversarial testing methodologies. The human-sourced category's higher accuracy across all models implies that human-curated evaluations may better reflect real-world jailbreak challenges, offering insights for model refinement.