\n
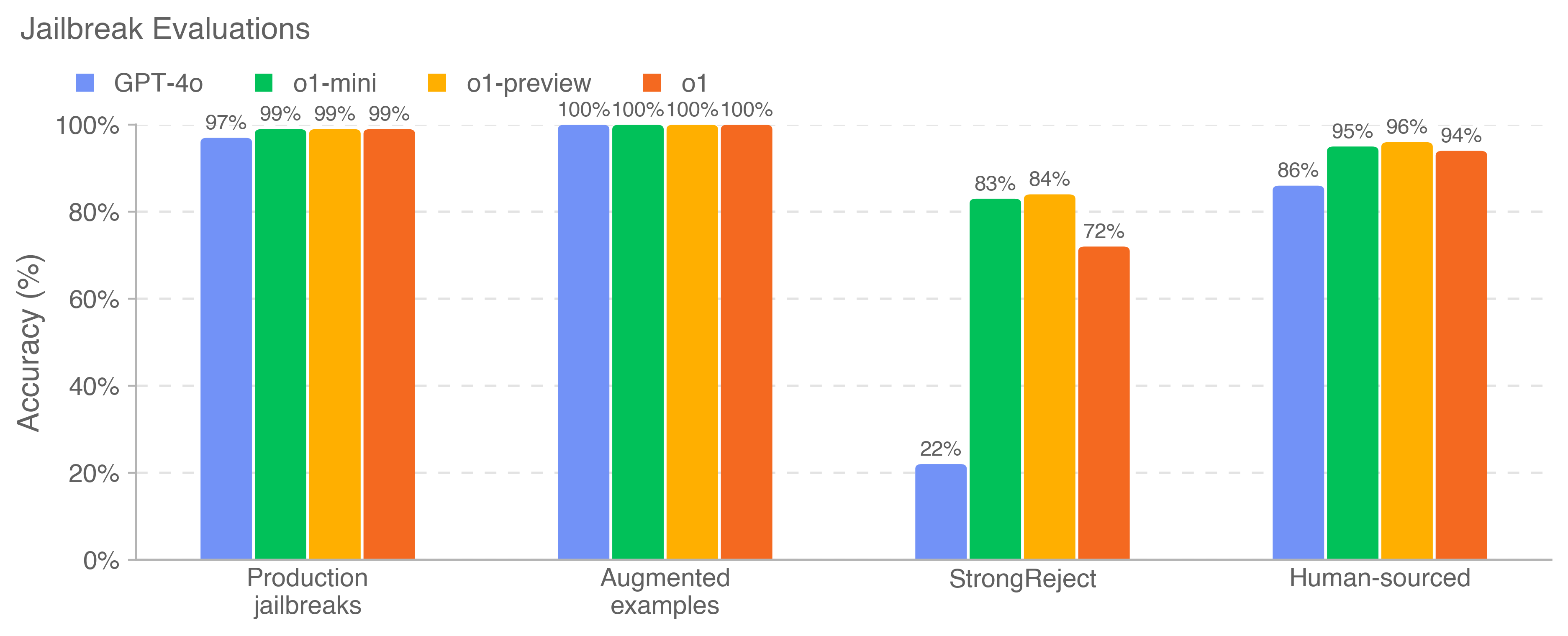
## Bar Chart: Jailbreak Evaluations
### Overview
This bar chart compares the accuracy of four different models (GPT-4o, o1-mini, o1-preview, and o1) across four different types of jailbreak evaluations: Production jailbreaks, Augmented examples, StrongReject, and Human-sourced. Accuracy is measured as a percentage.
### Components/Axes
* **Title:** Jailbreak Evaluations
* **X-axis:** Evaluation Type (Production jailbreaks, Augmented examples, StrongReject, Human-sourced)
* **Y-axis:** Accuracy (%) - Scale ranges from 0% to 100% with increments of 20%.
* **Legend:** Located at the top-left corner.
* GPT-4o (Blue)
* o1-mini (Teal/Cyan)
* o1-preview (Orange)
* o1 (Red)
### Detailed Analysis
The chart consists of four groups of bars, one for each evaluation type. Each group contains four bars, representing the accuracy of each model.
**Production jailbreaks:**
* GPT-4o: Approximately 97% accuracy.
* o1-mini: Approximately 99% accuracy.
* o1-preview: Approximately 99% accuracy.
* o1: Approximately 99% accuracy.
**Augmented examples:**
* GPT-4o: 100% accuracy.
* o1-mini: 100% accuracy.
* o1-preview: 100% accuracy.
* o1: 100% accuracy.
**StrongReject:**
* GPT-4o: Approximately 22% accuracy.
* o1-mini: Approximately 83% accuracy.
* o1-preview: Approximately 84% accuracy.
* o1: Approximately 72% accuracy.
**Human-sourced:**
* GPT-4o: Approximately 95% accuracy.
* o1-mini: Approximately 86% accuracy.
* o1-preview: Approximately 96% accuracy.
* o1: Approximately 94% accuracy.
### Key Observations
* All models achieve very high accuracy (97% - 100%) on "Production jailbreaks" and "Augmented examples".
* GPT-4o performs significantly worse than the other models on "StrongReject" evaluations (22% accuracy).
* o1-mini and o1-preview show the highest accuracy on "StrongReject" evaluations, at approximately 83% and 84% respectively.
* The accuracy scores for "Human-sourced" evaluations are generally high for all models, ranging from 86% to 96%.
### Interpretation
The data suggests that the models are generally robust against standard jailbreak attempts ("Production jailbreaks") and augmented examples. However, they struggle more with "StrongReject" evaluations, indicating a vulnerability to more sophisticated or targeted attacks. GPT-4o is particularly susceptible to these types of attacks. The high accuracy on "Human-sourced" evaluations suggests that the models are effective at identifying and rejecting jailbreak attempts crafted by humans.
The consistent high performance of o1-mini and o1-preview on "StrongReject" suggests they may have more effective defenses against these types of attacks compared to GPT-4o. The fact that all models achieve 100% accuracy on "Augmented examples" could indicate that the augmentation process is making the jailbreak attempts more easily detectable.
The differences in performance across the different evaluation types highlight the importance of using a diverse set of evaluation methods to assess the robustness of language models against jailbreak attacks.