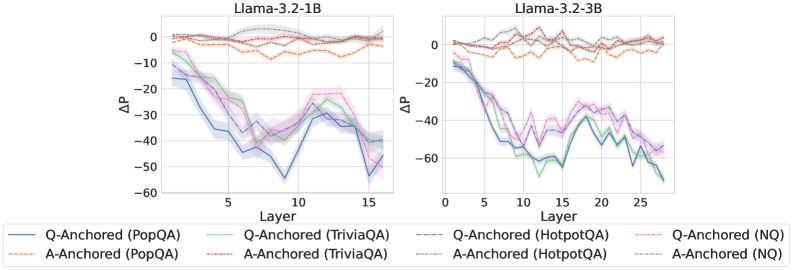
## Line Charts: Llama-3.2 Model Layer-wise Performance Delta (ΔP)
### Overview
The image displays two side-by-side line charts comparing the performance delta (ΔP) across the layers of two different-sized language models: Llama-3.2-1B (left) and Llama-3.2-3B (right). The charts track the performance of eight different experimental conditions, which are combinations of two anchoring methods ("Q-Anchored" and "A-Anchored") applied to four different question-answering datasets (PopQA, TriviaQA, HotpotQA, NQ).
### Components/Axes
* **Chart Titles:** "Llama-3.2-1B" (left chart), "Llama-3.2-3B" (right chart).
* **Y-axis:** Labeled "ΔP" (Delta P). The scale is negative, ranging from 0 down to -60 for the 1B model and 0 down to -80 for the 3B model. This indicates a performance decrease.
* **X-axis:** Labeled "Layer". The 1B model chart shows layers from approximately 1 to 15. The 3B model chart shows layers from 0 to approximately 27.
* **Legend:** Positioned at the bottom, spanning both charts. It defines eight series:
* **Q-Anchored (Solid Lines):**
* Blue: PopQA
* Green: TriviaQA
* Purple: HotpotQA
* Pink: NQ
* **A-Anchored (Dashed Lines):**
* Orange: PopQA
* Red: TriviaQA
* Brown: HotpotQA
* Gray: NQ
### Detailed Analysis
**Llama-3.2-1B Chart (Left):**
* **A-Anchored Series (Dashed Lines):** All four series (Orange, Red, Brown, Gray) remain clustered near the top of the chart, fluctuating between approximately ΔP = 0 and ΔP = -10 across all 15 layers. Their trend is relatively flat with minor oscillations.
* **Q-Anchored Series (Solid Lines):** All four series show a pronounced downward trend.
* They start between ΔP = -10 and -20 at Layer 1.
* They experience a steep decline, reaching their lowest points (troughs) between Layers 8 and 12. The blue line (PopQA) reaches the lowest point, approximately ΔP = -55 around Layer 10.
* After the trough, they show a partial recovery, rising back to between ΔP = -30 and -45 by Layer 15.
* The lines are tightly grouped, with the blue (PopQA) and green (TriviaQA) lines generally performing slightly worse (more negative) than the purple (HotpotQA) and pink (NQ) lines.
**Llama-3.2-3B Chart (Right):**
* **A-Anchored Series (Dashed Lines):** Similar to the 1B model, these series remain near the top, fluctuating between ΔP = 0 and ΔP = -15 across all ~27 layers. The trend is flat with noise.
* **Q-Anchored Series (Solid Lines):** These show a more severe and sustained decline compared to the 1B model.
* They start near ΔP = -10 at Layer 0.
* They drop sharply, reaching a deep trough between Layers 10 and 15. The green line (TriviaQA) appears to hit the lowest point, approximately ΔP = -70 around Layer 12.
* Following the trough, there is a modest recovery, but the values remain deeply negative, ending between ΔP = -50 and -70 at Layer 27.
* The grouping is similar to the 1B model, with PopQA (blue) and TriviaQA (green) consistently at the bottom of the cluster.
### Key Observations
1. **Fundamental Dichotomy:** There is a stark, consistent separation between the performance of A-Anchored methods (dashed lines, near-zero ΔP) and Q-Anchored methods (solid lines, large negative ΔP) across both model sizes and all four datasets.
2. **Layer-wise Degradation Pattern:** Q-Anchored performance degrades significantly in the middle layers (roughly layers 8-15 for 1B, 10-20 for 3B) before a partial recovery in later layers. This creates a distinct "U" or "V" shaped curve.
3. **Model Size Effect:** The larger Llama-3.2-3B model exhibits a more severe performance drop (ΔP reaching ~-70 vs. ~-55) and a longer degradation phase across more layers compared to the 1B model.
4. **Dataset Consistency:** The relative ordering of datasets within each anchoring group is fairly consistent. For Q-Anchored, PopQA and TriviaQA generally show the worst performance, while HotpotQA and NQ are slightly better.
### Interpretation
This data suggests a critical finding about how these Llama-3.2 models process information internally for question-answering tasks. The "ΔP" metric likely measures the change in performance or probability attributed to a specific layer's representations.
* **Anchoring Method is Paramount:** The anchoring strategy (question vs. answer) has a far greater impact on layer-wise performance than the specific dataset or even the model size. Using an answer anchor (A-Anchored) preserves performance across all layers, while a question anchor (Q-Anchored) leads to severe degradation in mid-to-late layers.
* **Mid-Layer Vulnerability:** The middle layers of the transformer appear to be a bottleneck or transformation zone where question-anchored representations become less useful or more noisy for the final prediction task. The partial recovery in later layers suggests some re-calibration or refinement occurs.
* **Scaling Amplifies the Effect:** The larger model's more pronounced drop indicates that this mid-layer degradation phenomenon is not only consistent but may be amplified with scale, potentially due to more specialized or complex internal processing.
* **Practical Implication:** For tasks or interpretability methods that rely on inspecting or manipulating internal model states (like activation patching or representation analysis), the choice of anchor point is crucial. Using answer-based anchors appears to yield more stable and interpretable signals across the model's depth, whereas question-based anchors reveal a specific, dynamic vulnerability in the model's processing pipeline.