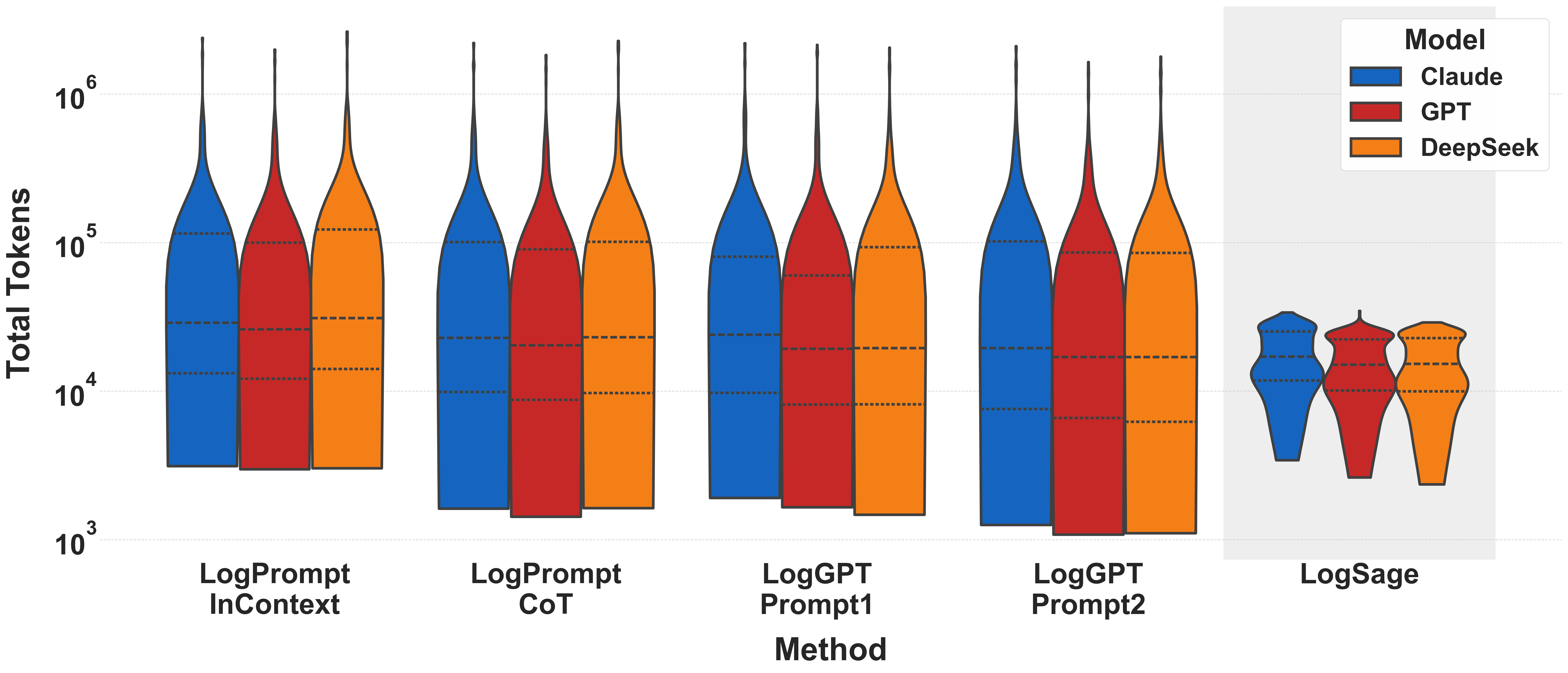
# Technical Analysis of Violin Plot: Token Usage Comparison Across Models
## **Chart Overview**
This violin plot compares the distribution of **Total Tokens** across different **Methods** for three AI models: **Claude** (blue), **GPT** (red), and **DeepSeek** (orange). The y-axis uses a logarithmic scale to represent token counts, while the x-axis categorizes methods.
---
## **Key Components**
### **1. Axes**
- **X-Axis (Method):**
Categories of evaluation methods:
- LogPrompt InContext
- LogPrompt CoT
- LogGPT Prompt1
- LogGPT Prompt2
- LogSage
- **Y-Axis (Total Tokens):**
Logarithmic scale ranging from **10³ to 10⁶**.
- Dashed horizontal lines indicate quartiles (25th, 50th, 75th percentiles) within each violin plot.
### **2. Legend**
- **Models:**
- **Claude** (blue)
- **GPT** (red)
- **DeepSeek** (orange)
---
## **Data Trends**
### **1. General Observations**
- **LogSage** consistently shows the **lowest token usage** across all models compared to other methods.
- **LogPrompt InContext** and **LogPrompt CoT** exhibit the highest token variability, with **Claude** generally consuming the most tokens.
- **LogGPT Prompt1** and **LogGPT Prompt2** show moderate token usage, with **DeepSeek** often outperforming the other models in efficiency.
### **2. Model-Specific Insights**
- **Claude (Blue):**
- Dominates in **LogPrompt InContext** and **LogPrompt CoT** with the highest median token counts.
- Shows reduced efficiency in **LogGPT Prompt1** and **LogGPT Prompt2** but remains above **DeepSeek**.
- **GPT (Red):**
- Outperforms **Claude** in **LogPrompt CoT** and **LogGPT Prompt2** but lags behind **DeepSeek** in most methods.
- **DeepSeek (Orange):**
- Consistently achieves the **lowest token counts** across all methods, particularly in **LogSage**.
- Demonstrates the most efficient token usage in **LogPrompt InContext** and **LogPrompt CoT**.
---
## **Inset Summary (LogSage)**
A zoomed-in view of the **LogSage** method highlights:
- **Claude**: Median ~10⁴ tokens.
- **GPT**: Median ~10³ tokens.
- **DeepSeek**: Median ~10³ tokens.
- **Key Insight:** DeepSeek and GPT are nearly identical in efficiency for LogSage, while Claude remains significantly higher.
---
## **Critical Notes**
1. **Logarithmic Scale Implications:**
- The y-axis compression emphasizes differences in token usage at lower magnitudes (e.g., 10³–10⁴).
- Higher values (e.g., 10⁵–10⁶) are less granular due to the scale.
2. **Quartile Lines:**
- Dashed lines within each violin plot indicate:
- Lower quartile (25th percentile)
- Median (50th percentile)
- Upper quartile (75th percentile)
3. **Model Consistency:**
- **DeepSeek** outperforms other models in **all methods**, especially in **LogSage**.
- **Claude** underperforms in efficiency across most methods but excels in **LogPrompt InContext**.
---
## **Conclusion**
The chart underscores **DeepSeek** as the most token-efficient model across all evaluated methods, with **LogSage** being the optimal method for minimizing token usage. **Claude** and **GPT** show method-dependent performance, with Claude favoring **LogPrompt InContext** and GPT performing better in **LogGPT Prompt2**.