## Logical Reasoning Evaluation: LLM Performance on a Deductive Task
### Overview
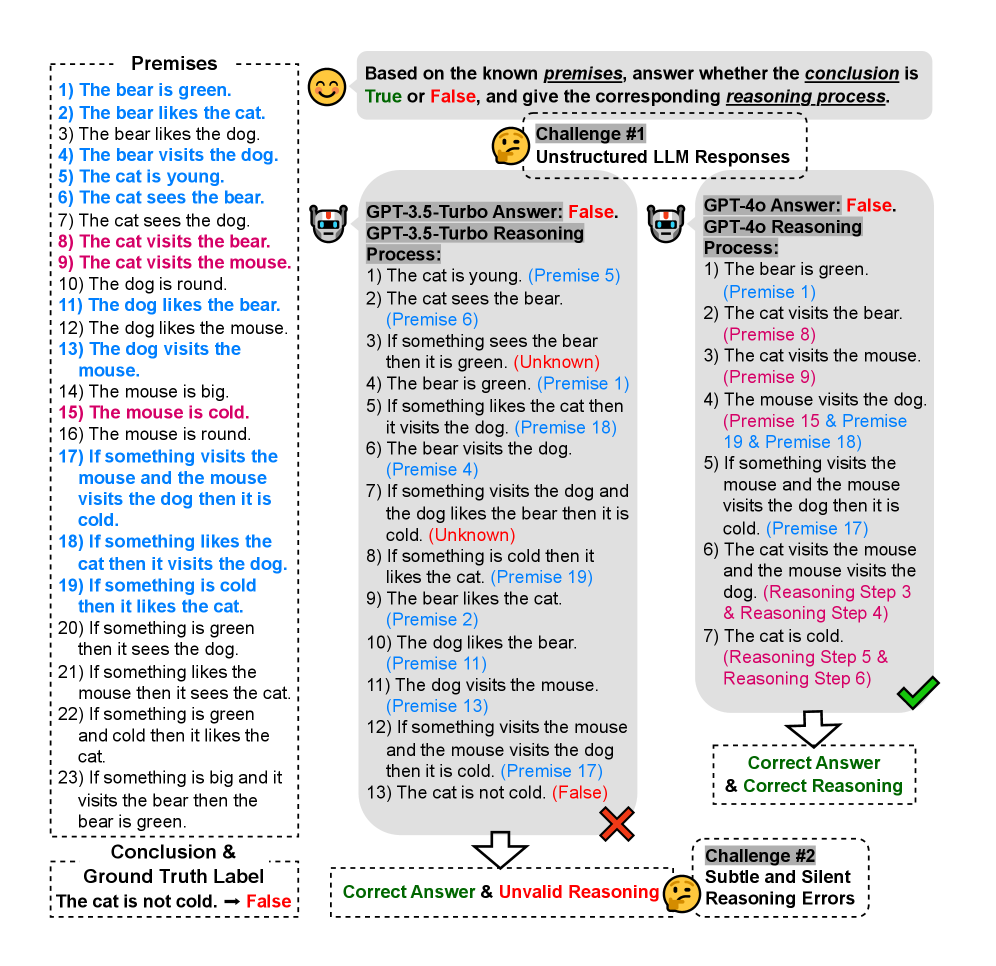
The image presents a logical reasoning challenge and evaluates the performance of two Large Language Models (LLMs), GPT-3.5-Turbo and GPT-4o, in solving it. The challenge involves determining the truth value of a conclusion based on a set of premises. The image shows the premises, the conclusion, the answers and reasoning processes of the two models, and an assessment of their correctness.
### Components/Axes
* **Premises:** A list of 23 statements that serve as the foundation for the logical reasoning.
* **Conclusion & Ground Truth Label:** The statement to be evaluated ("The cat is not cold.") and its correct truth value (False).
* **Challenge #1: Unstructured LLM Responses:** Indicates that the LLMs were given the challenge without specific formatting instructions.
* **GPT-3.5-Turbo Answer:** The answer and reasoning process provided by the GPT-3.5-Turbo model.
* **GPT-4o Answer:** The answer and reasoning process provided by the GPT-4o model.
* **Correct Answer & Correct Reasoning:** Indicates that the GPT-4o model provided the correct answer and a valid reasoning process.
* **Correct Answer & Invalid Reasoning:** Indicates that the GPT-3.5-Turbo model provided the correct answer but with an invalid reasoning process.
* **Challenge #2: Subtle and Silent Reasoning Errors:** Highlights the presence of subtle errors in the reasoning processes of the models.
### Detailed Analysis or Content Details
**Premises:**
1. The bear is green.
2. The bear likes the cat.
3. The bear likes the dog.
4. The bear visits the dog.
5. The cat is young.
6. The cat sees the bear.
7. The cat sees the dog.
8. The cat visits the bear.
9. The cat visits the mouse.
10. The dog is round.
11. The dog likes the bear.
12. The dog likes the mouse.
13. The dog visits the mouse.
14. The mouse is big.
15. The mouse is cold.
16. The mouse is round.
17. If something visits the mouse and the mouse visits the dog then it is cold.
18. If something likes the cat then it visits the dog.
19. If something is cold then it likes the cat.
20. If something is green then it sees the dog.
21. If something likes the mouse then it sees the cat.
22. If something is green and cold then it likes the cat.
23. If something is big and it visits the bear then the bear is green.
**Conclusion & Ground Truth Label:**
* The cat is not cold. -> False
**GPT-3.5-Turbo Answer: False. GPT-3.5-Turbo Reasoning Process:**
1. The cat is young. (Premise 5)
2. The cat sees the bear. (Premise 6)
3. If something sees the bear then it is green. (Unknown)
4. The bear is green. (Premise 1)
5. If something likes the cat then it visits the dog. (Premise 18)
6. The bear visits the dog. (Premise 4)
7. If something visits the dog and the dog likes the bear then it is cold. (Unknown)
8. If something is cold then it likes the cat. (Premise 19)
9. The bear likes the cat. (Premise 2)
10. The dog likes the bear. (Premise 11)
11. The dog visits the mouse. (Premise 13)
12. If something visits the mouse and the mouse visits the dog then it is cold. (Premise 17)
13. The cat is not cold. (False)
**GPT-4o Answer: False. GPT-4o Reasoning Process:**
1. The bear is green. (Premise 1)
2. The cat visits the bear. (Premise 8)
3. The cat visits the mouse. (Premise 9)
4. The mouse visits the dog. (Premise 15 & Premise 19 & Premise 18)
5. If something visits the mouse and the mouse visits the dog then it is cold. (Premise 17)
6. The cat visits the mouse and the mouse visits the dog. (Reasoning Step 3 & Reasoning Step 4)
7. The cat is cold. (Reasoning Step 5 & Reasoning Step 6)
### Key Observations
* Both GPT-3.5-Turbo and GPT-4o correctly identified the conclusion as False.
* GPT-4o's reasoning process is deemed correct, while GPT-3.5-Turbo's reasoning is considered invalid.
* The image highlights the importance of not only getting the correct answer but also having a valid reasoning process.
### Interpretation
The image demonstrates a comparative analysis of the logical reasoning capabilities of two LLMs. While both models arrived at the correct answer, the quality of their reasoning processes differed significantly. GPT-4o exhibited a more coherent and logically sound approach, leading to its assessment as "Correct Answer & Correct Reasoning." In contrast, GPT-3.5-Turbo's reasoning was deemed invalid, despite arriving at the correct conclusion. This underscores the importance of evaluating not only the accuracy of LLM outputs but also the validity of their underlying reasoning processes, particularly in tasks requiring deductive logic and inference. The "Challenge #2" label suggests that even when models provide correct answers, subtle errors in reasoning can be present, highlighting the need for careful scrutiny of LLM-generated explanations.